Bochs具有非常强大的操作系统内核调试功能。这也是本文选择Bochs作为首选实验环境的主要原因之一。有关Bochs调试功能的说明参见前面14.2节,这里基于Linux 0.11内核来说明Windows环境下Bochs系统调试操作的基本方法。14.8.1 运行Bochs调试程序
我们假设Bochs系统已被安装在目录“C:\Program Files\Bochs-2.1.1\”中,并且Linux 0.11系统的Bochs配置文件名称是bochsrc-hd.bxrc。现在在包含内核Image文件的目录下建立一个简单的批处理文件run.bat,其内容如下:
"C:\Program Files\Bochs-2.1.1\bochsdbg" -q -f bochsrc-hd.bxrc
其中bochsdbg是Bochs系统的调试执行程序。运行该批处理命令即可进入调试环境。此时Bochs的主显示窗口空白,而控制窗口将显示以下类似内容:
C:\Documents and Settings\john1\桌面\Linux-0.11>"C:\Program Files\Bochs-2.1.1\bo
chsdbg" -q -f bochsrc-hd.bxrc
========================================================================
Bochs x86 Emulator 2.1.1
February 08, 2004
========================================================================
00000000000i[ ] reading configuration from bochsrc-hd.bxrc
00000000000i[ ] installing win32 module as the Bochs GUI
00000000000i[ ] Warning: no rc file specified.
00000000000i[ ] using log file bochsout.txt
Next at t=0
(0) context not implemented because BX_HAVE_HASH_MAP=0
[0x000ffff0] f000:fff0 (unk. ctxt): jmp f000:e05b ; ea5be000f0
<bochs:1>
此时Bochs调试系统已经准备好开始运行,CPU执行指针已指向ROM BIOS中地址0x000fffff0处的指令处。其中'<bochs:1>'是命令输入提示符,其中的数字表示当前的命令序列号。在命令提示符'<bochs:1>'后面键入'help'命令,可以列出调试系统的基本命令。若要了解某个命令的具体使用方法,可以键入'help'命令并且后面跟随一个用单引号括住的具体命令,例如:“help 'vbreak'”,如下面所示。
<bochs:1> help
help - show list of debugger commands
help 'command'- show short command description
-*- Debugger control -*-
help, q|quit|exit, set, instrument, show, trace-on, trace-off,
record, playback, load-symbols, slist
-*- Execution control -*-
c|cont, s|step|stepi, p|n|next, modebp
-*- Breakpoint management -*-
v|vbreak, lb|lbreak, pb|pbreak|b|break, sb, sba, blist,
bpe, bpd, d|del|delete
-*- CPU and memory contents -*-
x, xp, u|disas|disassemble, r|reg|registers, setpmem, crc, info, dump_cpu,
set_cpu, ptime, print-stack, watch, unwatch, ?|calc
<bochs:2> help 'vbreak'
help vbreak
vbreak seg:off - set a virtual address instruction breakpoint
<bochs:3>
为了让Bochs直接模拟执行到Linux的引导启动程序开始处,我们可以先使用断点命令在0x7c00处设置一个断点,然后让系统连续运行到0x7c00处停下来。执行的命令序列如下:
<bochs:3> vbreak 0x0000:0x7c00
<bochs:4> c
(0) Breakpoint 1, 0x7c00 (0x0:0x7c00)
Next at t=4409138
(0) [0x00007c00] 0000:7c00 (unk. ctxt): mov ax, 0x7c0 ; b8c007
<bochs:5>
此时,CPU执行到boot.s程序开始处的第1条指令处,Bochs主窗口将显示出“Boot From floppy...”等一些信息。现在,我们可以利用单步执行命令's'或'n'(不跟踪进入子程序)来跟踪调试程序了。在调试时可以使用Bochs的断点设置命令、反汇编命令、信息显示命令等来辅助我们的调试操作。下面是一些常用命令的示例:
<bochs:8> u /10 # 反汇编从当前地址开始的10条指令。
00007c00: ( ): mov ax, 0x7c0 ; b8c007
00007c03: ( ): mov ds, ax ; 8ed8
00007c05: ( ): mov ax, 0x9000 ; b80090
00007c08: ( ): mov es, ax ; 8ec0
00007c0a: ( ): mov cx, 0x100 ; b90001
00007c0d: ( ): sub si, si ; 29f6
00007c0f: ( ): sub di, di ; 29ff
00007c11: ( ): rep movs word ptr [di], word ptr [si] ; f3a5
00007c13: ( ): jmp 9000:0018 ; ea18000090
00007c18: ( ): mov ax, cs ; 8cc8
<bochs:9> info r # 查看当前CPU寄存器的内容
eax 0xaa55 43605
ecx 0x110001 1114113
edx 0x0 0
ebx 0x0 0
esp 0xfffe 0xfffe
ebp 0x0 0x0
esi 0x0 0
edi 0xffe4 65508
eip 0x7c00 0x7c00
eflags 0x282 642
cs 0x0 0
ss 0x0 0
ds 0x0 0
es 0x0 0
fs 0x0 0
gs 0x0 0
<bochs:10> print-stack # 显示当前堆栈的内容
0000fffe [0000fffe] 0000
00010000 [00010000] 0000
00010002 [00010002] 0000
00010004 [00010004] 0000
00010006 [00010006] 0000
00010008 [00010008] 0000
0001000a [0001000a] 0000
...
<bochs:11> dump_cpu # 显示CPU中的所有寄存器和状态值。
eax:0xaa55
ebx:0x0
ecx:0x110001
edx:0x0
ebp:0x0
esi:0x0
edi:0xffe4
esp:0xfffe
eflags:0x282
eip:0x7c00
cs:s=0x0, dl=0xffff, dh=0x9b00, valid=1
ss:s=0x0, dl=0xffff, dh=0x9300, valid=7
ds:s=0x0, dl=0xffff, dh=0x9300, valid=1
es:s=0x0, dl=0xffff, dh=0x9300, valid=1
fs:s=0x0, dl=0xffff, dh=0x9300, valid=1
gs:s=0x0, dl=0xffff, dh=0x9300, valid=1
ldtr:s=0x0, dl=0x0, dh=0x0, valid=0
tr:s=0x0, dl=0x0, dh=0x0, valid=0
gdtr:base=0x0, limit=0x0
idtr:base=0x0, limit=0x3ff
dr0:0x0
dr1:0x0
dr2:0x0
dr3:0x0
dr6:0xffff0ff0
dr7:0x400
tr3:0x0
tr4:0x0
tr5:0x0
tr6:0x0
tr7:0x0
cr0:0x60000010
cr1:0x0
cr2:0x0
cr3:0x0
cr4:0x0
inhibit_mask:0
done
<bochs:12>
由于Linux 0.11内核的32位代码是从绝对物理地址0处开始存放的,因此若想直接执行到32位代码开始处,即head.s程序开始处,我们可以在线性地址0x0000处设置一个断点并运行命令'c'执行到那个位置处。
另外,当直接在命令提示符下打回车键时会重复执行上一个命令;按向上方向键会显示上一命令。其他命令的使用方法请参考'help'命令。
14.8.2 定位内核中的变量或数据结构
在编译内核时会产生一个system.map文件。该文件列出了内核Image (bootimage)文件中全局变量和各个模块中的局部变量的偏移地址位置。在内核编译完成后可以使用前面介绍的文件导出方法把system.map文件抽取到主机环境(windows)中。有关system.map文件的详细功能和作用请参见2.10.3节。system.map样例文件中的部分内容见如下所示。利用这个文件,我们可以在Bochs调试系统中快速地定位某个变量或跳转到指定的函数代码处。
...
Global symbols:
_dup: 0x16e2c
_nmi: 0x8e08
_bmap: 0xc364
_iput: 0xc3b4
_blk_dev_init: 0x10ed0
_open: 0x16dbc
_do_execve: 0xe3d4
_con_init: 0x15ccc
_put_super: 0xd394
_sys_setgid: 0x9b54
_sys_umask: 0x9f54
_con_write: 0x14f64
_show_task: 0x6a54
_buffer_init: 0xd1ec
_sys_settimeofday: 0x9f4c
_sys_getgroups: 0x9edc
...
同样,由于Linux 0.11内核的32位代码是从绝对物理地址0处开始存放的,system.map中全局变量的偏移位置值就是CPU中线性地址位置,因此我们可以直接在感兴趣的变量或函数名位置处设置断点,并让程序连续执行到指定的位置处。例如若我们想调试函数buffer_init(),那么从system.map文件中可以知道它位于0xd1ec处。此时我们可以在该处设置一个线性地址断点,并执行命令'c'让CPU执行到这个指定的函数开始处,见如下所示。
<bochs:12> lb 0xd1ec # 设置线性地址断点。
<bochs:13> c # 连续执行。
(0) Breakpoint 2, 0xd1ec in ?? ()
Next at t=16689666
(0) [0x0000d1ec] 0008:0000d1ec (unk. ctxt): push ebx ; 53
<bochs:14> n # 执行下一指令。
Next at t=16689667
(0) [0x0000d1ed] 0008:0000d1ed (unk. ctxt): mov eax, dword ptr ss:[esp+0x8] ; 8b442408
<bochs:15> n # 执行下一指令。
Next at t=16689668
(0) [0x0000d1f1] 0008:0000d1f1 (unk. ctxt): mov edx, dword ptr [ds:0x19958] ; 8b1558990100
<bochs:16>
程序调试是一种技能,需要多练习才能熟能生巧。上面介绍的一些基本命令需要组合在一起使用才能灵活地观察到内核代码执行的整体环境情况。
Bochs使用简单教程
Bochs是一个开源的虚拟机。它可以实现vpc和vmware的大部分功能。你也可以像使用vmware一样的在Bochs里面安装操作系统。但是,由于它是全模拟的。所以,速度要远远慢于vmware.这样看来Bochs好像没有什么优势.是这样吗?在应用方面的确如此。
但是,在其他一个方面它是处于绝对优势的。那就是它具有调试功能!这是一个让人振奋的功能。这个功能在你调试操作系统或者其他一些在裸机上运行的程序时候,会让你有一种在写windows下运行的应用程序的感觉。有时候它是我们的救命稻草。没了它,也能活,但是肯定要糟糕的多。好了我们开始切入正题。
一、 配置Bochs
实际上配置Bochs是很简单的,为什么很多人不会配置呢?我觉的就是因为他使用和配置方式和普通程序不一样——配置文件。实际上配置文件是和ini文件、bat文件类似的。Bochs没有给我们提供图形界面的配置工具。这就需要我们自己来修改配置文件。
简单的配置就可以让你的操作系统在Bochs里面跑起来。用Bochs跑完整的linux和windows是不现实的。实在是太慢了。一般我们也只能把他当成调试器来使用。现在,我们先看一下如何让dos在他里面跑起来。如果你细心的话你会发现在Bochs文件夹里面有一个Bochsrc-sample.txt的文本文件。里面包含了所有了Bochs参数的信息。这个是官方的教程。可惜是英文的,而且我也没有找到有中文的教程(不然也没有我这篇文章)。在这里我们仅仅介绍最简单的配置选项。好了,废话就不多说了。我们现在就开始。
我们以一个例子来说明,这个例子是我用来跑dos以及我自己的小操作系统的。下面就是我们要用到的最基本的选项:
# 在一行的最前面加上“#”表示这一行是注释行。
# 内存,以MB为单位,对于dos来说最大可以访问16MB
# 的内存,所以我就给了他16MB,你可以根据自己的机器来调整
megs: 16
# 下面两句一般是不可以改的,至于干什么用的就不用我说
# 了。从他们的文件名就可以看出来。
romimage: file=../BIOS-Bochs-latest, address=0xf0000
vgaromimage: file=../VGABIOS-lgpl-latest
# 这个还用说吗?当然是软驱了,我想我们写操作系统肯定是先
# 把操作系统放在软盘(或映像)里面吧?在Bochs里面是可
# 以使用任意大小的软驱映像的。可以是1.44或2.88,我一般使
# 用2.88。还有就是Bochs里面可以使用两个软驱。不过好像
# 我们并不经常这样做。
floppya: 2_88=test.img, status=inserted
#floppyb: 1_44=floppyb.img, status=inserted
# 下面是硬盘,很简单,还有就是Bochs也是可以支持多个硬
# 盘的。那么,硬盘文件是怎么生成的呢?我们可以发现硬盘是
# img格式的。你注意没有在Bochs文件夹里有一个工具叫
# bximage.exe,我想你应该猜出来了。他就是用来生成这个硬盘
# 文件的工具。我在这儿还想说的是硬盘分三种格式的,最好选
#用growing类型。这种有一个好处就是节省硬盘空间,不过使用
#这种类型的硬盘还需要在下面加上mode = growing这个选项。
ata0: enabled=1, ioaddr1=0x1f0, ioaddr2=0x3f0, irq=14
ata0-master: type=disk, path="dos.img", cylinders=306, heads=4, spt=17
# 下面这个就是光驱,没什么好说的。如果你想使用物理光驱,
# 只要让path=E:(我们假设E盘是光驱)
ata0-slave: type=cdrom, path="dos.iso", status=inserted
# 这个是启动设备,可以使用cdrom(光驱)、c(硬盘)或floppy(软
# 驱)。
#boot: cdrom
boot: c
#boot: floppy
# 这一句可以不要,他只是指定用来保存日志的文件。如果不指定的
# 话他就会输出到命令控制台上。
log: Bochsout.txt
# 这一句是设置在开机时是否激活鼠标,Bochs对于鼠标的控制不是# 很好。建议如果不是特别需要的话不要激活他。在运行期间也可以点窗口右上角的鼠标图标来激活他。
mouse: enabled=0
以上这些设置就可以让你的DOS或自己的小操作系统在Bochs里面跑起来了。至于其他的一些高级支持,你可以查看Bochsrc-sample.txt里面的说明。不要害怕他,其实很简单。关键是抛弃恐惧。
二、 启动Bochs
配置文件已经写好了,硬盘文件等也都已经弄好了。那么我们如何来启动Bochs呢?很简单,你右击一下上面写的那个配置文件(例如myos.bxrc,注意:扩展名要是.bxrc。)选择“运行”或双击即可。不过我一般都不这样做,我一般是写一个批处理文件。
很简单,如下所示:
cd "d:\Bochs-2.2.1\dos"
..\Bochs.exe -q -f Bochsrc.bxrc
这样做的好处就是无论这个启动脚本放在哪儿都是可以使用的。那么,我们如何进入调试状态呢?下面我们就来讨论这个问题。
三、 调试功能
新建一个批处理文件,写入一下内容:
cd "d:\Bochs-2.2.1\dos"
..\Bochsdbg.exe -q -f Bochsrc.bxrc
运行这个批处理文件,你就可以进入调试状态了。不过你会发现,程序卡住了。没有想普通运行状态一样进入你的dos操作系统。为什么?因为调试在等待你的命令。你只有给他一个命令他才会继续。我们输入“c”,然后回车。是不是dos已经可是运行了?
如果没有运行说明你输入的窗口不对,你不会把c输入到那个没有光标的窗口了吧?如果真是那样我真是服了你了。真的!但是,dos运行起来了,如何在返回调试状态?很简单,按ctrl+c。什么你正在运行的程序被结束了?谁让你在操作系统窗口中按了,我是说在调试窗口按。至于哪个是调试窗口,哪个是操作系统窗口,我就不说了。如果你不知道你就干脆别使用Bochs了,也不要写什么程序了,更不要开发什么操作系统了。为什么?因为你不可能成功。从这儿就可以看出来。最好是找块豆腐撞死,这样你会很幸福的死去,不然你就会成为教育后代的典范——看到了吗XXX是怎么死的,笨死的。呵呵!开个玩笑。你真要不知道
千万不要来找我,找我我也不告诉你。不好意思,我也不知道。那么,在调试状态下我们可以干哪些事呢?你用过debug吗?它能做的Bochs都能做,它不能做的Bochs也可以做。下面就是一些常用的调试命令。
help
我最想告诉大家的是这个指令,因为他可以告诉我们一切。古语说:“授之以鱼,不若授之以渔”。我觉的很有道理。但是,有些人就是不想学这种一劳永逸的方法。所以,我还要继续写下去。
输入help,回车。你会得到以下信息:
help - show list of debugger commands
help 'command'- show short command description
-*- Debugger control -*-
help, q|quit|exit, set, instrument, show, trace-on, trace-off,
record, playback, load-symbols, slist
-*- Execution control -*-
c|cont, s|step|stepi, p|n|next, modebp
-*- Breakpoint management -*-
vb|vbreak, lb|lbreak, pb|pbreak|b|break, sb, sba, blist,
bpe, bpd, d|del|delete
-*- CPU and memory contents -*-
x, xp, u|disas|disassemble, r|reg|registers, setpmem, crc, info, dump_cpu,
set_cpu, ptime, print-stack, watch, unwatch, ?|calc
需不需要我翻译一下前两句?那好吧。
help - 现实调试命令列表
help '命令' - 显示某条命令的详细用法。
命令分为哪些?很明显,四类:调试控制,运行控制,断点管理,CPU和内存控制。我不想在这儿一一介绍了。没有必要,我只介绍一下最常用的就可以了。
c:继续,前面我们已经用过了。
s:单步执行。他还有一个扩展用法。
s n :执行n步。
b 0x7c00:在内存0x7c00处设置一个断点.当程序执行到0x7c00处就自动进入到调试状态.后面的这个数指的是内存的线性地址
。也可以使用10进制的数,但是好像没有人会这样做。
x /20 0x7c00: 以16进制的形式从内存的0x7c00开始显示20个字的数据。这个是很常用的命令,但是需要注意的是他的显示顺序和16进制编辑器中的显示顺序有一点小的区别。他的显示是以字为单位的,而且在字中是从低到高显示的.不过也没有什么大不了的。你只要稍微注意一下就可以了。
dump_cpu:这个是我最长用的三个指令之一。他的功能是显示现在的寄存器的状态,详细内容类似于:
eax:0x00000000, ebx:0x00000000, ecx:0x00000000, edx:0x00000683
ebp:0x00000000, esp:0x00000000, esi:0x00000000, edi:0x00000000
eip:0x0000fff0, eflags:0x00000002, inhibit_mask:0
cs:s=0xf000, dl=0x0000ffff, dh=0xff009bff, valid=1
ss:s=0x0000, dl=0x0000ffff, dh=0x00009300, valid=1
ds:s=0x0000, dl=0x0000ffff, dh=0x00009300, valid=1
es:s=0x0000, dl=0x0000ffff, dh=0x00009300, valid=1
fs:s=0x0000, dl=0x0000ffff, dh=0x00009300, valid=1
gs:s=0x0000, dl=0x0000ffff, dh=0x00009300, valid=1
ldtr:s=0x0000, dl=0x00000000, dh=0x00000000, valid=0
tr:s=0x0000, dl=0x00000000, dh=0x00000000, valid=0
gdtr:base=0x00000000, limit=0xffff
idtr:base=0x00000000, limit=0xffff
dr0:0x00000000, dr1:0x00000000, dr2:0x00000000
dr3:0x00000000, dr6:0xffff0ff0, dr7:0x00000400
cr0:0x00000010, cr1:0x00000000, cr2:0x00000000
cr3:0x00000000, cr4:0x00000000
u /20 0x7c00 :反汇编内存0x7c00处,反汇编的长度是20。你想不想知道dos的引导程序是什么样子的?执行一下这个命令就可以了。你还可以使用这样的命令 u /20 cs:0x120a,至于什么意思,我也不说了。
现在,我们已经介绍了6条命令了。够了。对于日常应用已经完全够用了。如果你想了解其他命令的用法只要执行一下help “命令名”就可以了(注意,命令上要带有引号)。好了。现在已经把Bochs的基本功能介绍完了。你是不是感觉Bochs很简单?对于简单的应用来说,确实如此。但是,想让他支持一些高级功能就有点麻烦了。毕竟它是全模拟的虚拟机,所以在有些方面实现起来并不容易。但是,向网络之类的功能还是可以支持的。你只要看一下Bochsrc-sample.txt就知道了。我在这儿就不说了。我还要说的是Bochs不仅仅可以调试操作系统,还可以调试dos下的程序。我们知道dos没有多少好的调试器。那么我们完全可以使用Bochs来调试。你知道在程序的开头输出一下程序的段地址和偏移地址,然后暂定一下,在虚拟机里面设置一下断点就可以了。我一般都是在在程序里面潜入一句汇编:
jmp $
这样在程序死循环的时候在调试窗口按下ctrl+c就可以看到他的段地址和偏移地址了。然后,在去掉这一句,设置一下断点,运行这个程序。是不是在指定位置中断了?
一:配置
bochs.exe是执行模式,不能调试的。Bochs的调试工具是Bochsdbg.exe。同样,调试的时候你仍然需要进行配置。此时如果我们还使用双击.bxrc配置文件的方法显然是不行的(因为此时会运行Bochs.exe而不是Bochsdbg.exe)。所以我copy了《自己动手写操作系统》作者于渊的方法——使用bat批处理文件。
新建一个批处理文件然后进行编辑。以下内容为我的bat文件:
D:\Develop\Bochs-2.2.1\bochsdbg.exe -q -f config.bxrc
显然,首先要指定调试程序的位置,后面 –q –f表示退出配置选择文件配置,后面的config.bxrc就是刚才运行Bochs所使用的配置文件。下面重点看看如何进行调试。
二:调试
感觉Bochs的调试和DOS提供的Debug很相似——毕竟都是命令行式的调试。如果有一个像TurboDebugger这样的可视化调试工具就好了。(这段文章也是我从网上copy下来的,最后总结为表格的形式,以方便以后查阅)
说明:下面的“[]”表示可有可无的参数在写的时候不要写。
执行控制命令
Help 帮助命令,以下的命令都可以通过help命令查到。
c 继续执行,遇到断点将停止
stepi [count] 执行count条指令, 默认为1条
si [count] stepi的缩写
step [count] 执行count条指令, 默认为1条
s [count] step的缩写
Ctrl-C 停止执行,返回命令行
Ctrl-D 执行完所有命令后,退出
quit 退出调试器
q quit缩写
设置断点
vbreak seg:off 在指定的虚拟地址(段+偏移)设置断点,在保护模式下也可以使用
vb seg:off
lbreak addr 在一个线性地址设置断点
lb addr
pbreak [*] addr 在一个物理地址设置断点
pb [*] addr
break [*] addr
b [*] addr
info break 显示所有断点状态
例如:
--------------------------------------
Num Type Disp Enb Address
1 pbreakpoint keep y 0x00007c00
表示在物理地址0x00007c00设置一个断点,该断点目前有效
---------------------------------------
delete n 删除一个断点
del n
d n
关于物理地址,线性地址和虚拟地址的区别,我只能凭我的理解简单说说,可能不准确。物理地址在什么时候都存在,但是在采用分页技术和虚拟内存技术后,你很难确定物理地址在那里,所以建议在实模式下采用物理地址和线性地址形式,这时候物理地址和线性地址其实是一致的。最常用的,比方说,计算机启动后的地址是0xfff0:0000,装载BIOS,然后转移到0x07C0:0000,所以总可以设置一个物理断点0x7C00,开始调试你的bootloader。
查看内存
x /nuf addr 查看一个线性地址的内存
xp /nuf addr 查看一个物理地址的内存
n 显示多少个单位的内存
u 内存单位大小,可以是
b 字节
h 字(2个字节)
w 双字(4个字节)
g 4字(8字节)
注意: 它们不太符合Intel字节命名格式,但是遵守GDB约定。
f 打印格式,可以是
x 16进制格式打印
d 10进制格式打印
u 无符号10进制格式打印
o 8进制格式打印
t 2进制格式打印
n,f,和u是可选参数。U和f默认为你最后使用的参数, 如果是第一次使用,u默认为w,f默认为x, n默认为1。如果没有指定nuf,那么/也可以不要。setpmem addr datasize val 设置物理地址addr,大小datasize的内存单元的值为val.
crc addr1 addr2 对物理地址范围addr1到addr2进行CRC校验?(没用过)info dirty 显示写过的页?(没用过)
Info
info program 查看程序的执行状态
info registers 列举CPU整型寄存器遗迹它们的内容
info break 显示当前断点信息
where 打印当前call stack
寄存器操作
set $reg = val 改变寄存器的内容。可改变的寄存器有:
eax, ecx, edx, ebx, esp, ebp, esi, edi.
不可改变的寄存器有:
eflags, cs, ss, ds, es, fs, gs.
例如 set $eax = 0x01234567
set $edx = 25
info registers 显示寄存器内容
dump_cpu 查看所有与CPU相关的寄存器状态
set_cpu 设置所有与CPU相关的寄存器状态
dump_cpu和set_cpu格式如下:
"eax:0x%x\n"
"ebx:0x%x\n"
"ecx:0x%x\n"
"edx:0x%x\n"
"ebp:0x%x\n"
"esi:0x%x\n"
"edi:0x%x\n"
"esp:0x%x\n"
"eflags:0x%x\n"
"eip:0x%x\n"
"cs:s=0x%x, dl=0x%x, dh=0x%x, valid=%u\n"
"ss:s=0x%x, dl=0x%x, dh=0x%x, valid=%u\n"
"ds:s=0x%x, dl=0x%x, dh=0x%x, valid=%u\n"
"es:s=0x%x, dl=0x%x, dh=0x%x, valid=%u\n"
"fs:s=0x%x, dl=0x%x, dh=0x%x, valid=%u\n"
"gs:s=0x%x, dl=0x%x, dh=0x%x, valid=%u\n"
"ldtr:s=0x%x, dl=0x%x, dh=0x%x, valid=%u\n"
"tr:s=0x%x, dl=0x%x, dh=0x%x, valid=%u\n"
"gdtr:base=0x%x, limit=0x%x\n"
"idtr:base=0x%x, limit=0x%x\n"
"dr0:0x%x\n"
"dr1:0x%x\n"
"dr2:0x%x\n"
"dr3:0x%x\n"
"dr4:0x%x\n"
"dr5:0x%x\n"
"dr6:0x%x\n"
"dr7:0x%x\n"
"tr3:0x%x\n"
"tr4:0x%x\n"
"tr5:0x%x\n"
"tr6:0x%x\n"
"tr7:0x%x\n"
"cr0:0x%x\n"
"cr1:0x%x\n"
"cr2:0x%x\n"
"cr3:0x%x\n"
"cr4:0x%x\n"
"inhibit_int:%u\n"
"done\n"
命令
说明
断
点
相
关
vb seg:off vbreak
在指定的虚拟地址(段+偏移)设置断点,在保护模式下也可以使用
lb addr lbreak
在一个线性地址设置断点
Pb pbreak
在一个物理地址设置断点
info break
显示所有断点状态
del n delete n d n
删除一个断点
步
进
C
继续执行,遇到断点将停止
step [count]
执行count条指令, 默认为1条
内
存
寄
存
器
查
看
x /nuf addr
查看一个线性地址的内存
n 显示多少个单位的内存
u 内存单位大小:
可以是,b字节,h字,w 双字,g 4字
f 打印格式:
可以是:16进制,d 10进制,u 无符号10进制,o 8进制,t 2进制
xp /nuf addr
查看一个物理地址的内存
info registers
列举CPU整型寄存器遗迹它们的内容
反汇编
disassemble start end 反汇编的地址范围
set $disassemble_size = n 告诉调试器,反汇编段的属性(16位或32位,默认32位)。
---http://blog.chinaunix.net/u/15262/showart_411540.html
posted @
2016-09-20 17:23 yuhen 阅读(391) |
评论 (0) |
编辑 收藏通常情况下,在SMP系统中,Linux内核的进程调度器根据自有的调度策略将系统中的一个进程调度到某个CPU上执行。一个进程在前一个执行时间是在cpuM(M为系统中的某CPU的ID)上运行,而在后一个执行时间是在cpuN(N为系统中另一CPU的ID)上运行。这样的情况在Linux中是很可能发生的,因为Linux对进程执行的调度采用时间片法则(即进行用完自己的时间片即被暂停执行),而默认情况下,一个普通进程或线程的处理器亲和性是在所有可用的CPU上,有可能在它们之中的任何一个CPU(包括超线程)上执行。
进程的处理器亲和性(Processor Affinity),即是CPU的绑定设置,是指将进程绑定到特定的一个或多个CPU上去执行,而不允许调度到其他的CPU上。Linux内核对进程的调度算法也是遵守进程的处理器亲和性设置的。设置进程的处理器亲和性带来的好处是可以减少进程在多个CPU之间交换运行带来的缓存命中失效(cache missing),从该进程运行的角度来看,可能带来一定程度上的性能提升。换个角度来看,对进程亲和性的设置也可能带来一定的问题,如破坏了原有SMP系统中各个CPU的负载均衡(load balance),这可能会导致整个系统的进程调度变得低效。特别是在多处理器、多核、多线程技术使用的情况下,在NUMA(Non-Uniform Memory Access)[3]结构的系统中,如果不能基于对系统的CPU、内存等有深入的了解,对进程的处理器亲和性进行设置是可能导致系统的整体性能的下降而非提升。
每个vCPU都是宿主机中的一个普通的QEMU线程,可以使用taskset工具对其设置处理器亲和性,使其绑定到某一个或几个固定的CPU上去调度。尽管Linux内核的进程调度算法已经非常高效了,在多数情况下不需要对进程的调度进行干预,不过,在虚拟化环境中有时却有必要对客户机的QEMU进程或线程绑定到固定的逻辑CPU上。下面举一个云计算应用中需要绑定vCPU的实例。
作为IAAS(Infrastructure As A Service)类型的云计算提供商的A公司(如Amazon、Google、阿里云、盛大云等),为客户提供一个有2个逻辑CPU计算能力的一个客户机。要求CPU资源独立被占用,不受宿主机中其他客户机的负载水平的影响。为了满足这个需求,可以分为如下两个步骤来实现。
第一步,启动宿主机时隔离出两个逻辑CPU专门供一个客户机使用。在Linux内核启动的命令行加上“isolcpus=”参数,可以实现CPU的隔离,让系统启动后普通进程默认都不会调度到被隔离的CPU上执行。例如,隔离了cpu2和cpu3的grub的配置文件如下:
title Red Hat Enterprise Linux Server (3.5.0)
root (hd0,0)
kernel /boot/vmlinuz-3.5.0 ro root=UUID=1a65b4bb-cd9b-4bbf-97ff-7e1f7698d3db isolcpus=2,3
initrd /boot/initramfs-3.5.0.img
系统启动后,在宿主机中检查是否隔离成功,命令行如下:
[root@jay-linux ~]# ps -eLo psr | grep 0 | wc -l
106
[root@jay-linux ~]# ps -eLo psr | grep 1 | wc -l
107
[root@jay-linux ~]# ps -eLo psr | grep 2 | wc -l
4
[root@jay-linux ~]# ps -eLo psr | grep 3 | wc -l
4
[root@jay-linux ~]# ps -eLo ruser,pid,ppid,lwp,psr,args | awk ‘{if($5==2) print $0}’
root 10 2 10 2 [migration/2]
root 11 2 11 2 [kworker/2:0]
root 12 2 12 2 [ksoftirqd/2]
root 245 2 245 2 [kworker/2:1]
[root@jay-linux ~]# ps –eLo ruser,pid,ppid,lwp,psr,args | awk ‘{if($5==3) print $0}’
root 13 2 13 3 [migration/3]
root 14 2 14 3 [kworker/3:0]
root 15 2 15 3 [ksoftirqd/3]
root 246 2 246 3 [kworker/3:1]
从上面的命令行输出信息可知,cpu0和cpu1上分别有106和107个线程在运行,而cpu2和cpu3上都分别只有4个线程在运行。而且,根据输出信息中cpu2和cpu3上运行的线程信息(也包括进程在内),分别有migration进程(用于进程在不同CPU间迁移)、两个kworker进程(用于处理workqueues)、ksoftirqd进程(用于调度CPU软中断的进程),这些进程都是内核对各个CPU的一些守护进程,而没有其他的普通进程在cup2和cpu3上运行,说明对其的隔离是生效的。
另外,简单解释一下上面的一些命令行工具及其参数的意义。ps命令显示当前系统的进程信息的状态,它的“-e”参数用于显示所有的进程,“-L”参数用于将线程(LWP,light-weight process)也显示出来,“-o”参数表示以用户自定义的格式输出(其中“psr”这列表示当前分配给进程运行的处理器编号,“lwp”列表示线程的ID,“ruser”表示运行进程的用户,“pid”表示进程的ID,“ppid”表示父进程的ID,“args”表示运行的命令及其参数)。结合ps和awk工具的使用,是为了分别将在处理器cpu2和cpu3上运行的进程打印出来。
第二步,启动一个拥有2个vCPU的客户机并将其vCPU绑定到宿主机中两个CPU上。此操作过程的命令行如下:
#(启动一个客户机)
[root@jay-linux kvm_demo]# qemu-system-x86_64 rhel6u3.img -smp 2 -m 512 -daemonize
VNC server running on ‘::1:5900’
#(查看代表vCPU的QEMU线程)
[root@jay-linux ~]# ps -eLo ruser,pid,ppid,lwp,psr,args | grep qemu | grep -v grep
root 3963 1 3963 0 qemu-system-x86_64 rhel6u3.img -smp 2 -m 512 -daemonize
root 3963 1 3967 0 qemu-system-x86_64 rhel6u3.img -smp 2 -m 512 -daemonize
root 3963 1 3968 1 qemu-system-x86_64 rhel6u3.img -smp 2 -m 512 –daemonize
#(绑定代表整个客户机的QEMU进程,使其运行在cpu2上)
[root@jay-linux ~]# taskset -p 0x4 3963
pid 3963’s current affinity mask: 3
pid 3963’s new affinity mask: 4
#(绑定第一个vCPU的线程,使其运行在cpu2上)
[root@jay-linux ~]# taskset -p 0x4 3967
pid 3967’s current affinity mask: 3
pid 3967’s new affinity mask: 4
#(绑定第二个vCPU的线程,使其运行在cpu3上)
[root@jay-linux ~]# taskset -p 0x8 3968
pid 3968’s current affinity mask: 4
pid 3968’s new affinity mask: 8
#(查看QEMU线程的绑定是否生效,如下的第5列为处理器亲和性)
[root@jay-linux ~]# ps -eLo ruser,pid,ppid,lwp,psr,args | grep qemu | grep -v grep
root 3963 1 3963 2 qemu-system-x86_64 rhel6u3.img -smp 2 -m 512 -daemonize
root 3963 1 3967 2 qemu-system-x86_64 rhel6u3.img -smp 2 -m 512 -daemonize
root 3963 1 3968 3 qemu-system-x86_64 rhel6u3.img -smp 2 -m 512 –daemonize
#(执行vCPU的绑定后,查看在cpu2上运行的线程)
[root@jay-linux ~]# ps -eLo ruser,pid,ppid,lwp,psr,args | awk ‘{if($5==2) print $0}’
root 10 2 10 2 [migration/2]
root 11 2 11 2 [kworker/2:0]
root 12 2 12 2 [ksoftirqd/2]
root 245 2 245 2 [kworker/2:1]
root 3963 1 3963 2 qemu-system-x86_64 rhel6u3.img -smp 2 -m 512 -daemonize
root 3963 1 3967 2 qemu-system-x86_64 rhel6u3.img -smp 2 -m 512 -daemonize
#(执行vCPU的绑定后,查看在cpu3上运行的线程)
[root@jay-linux ~]# ps –eLo ruser,pid,ppid,lwp,psr,args | awk ‘{if($5==3) print $0}’
root 13 2 13 3 [migration/3]
root 14 2 14 3 [kworker/3:0]
root 15 2 15 3 [ksoftirqd/3]
root 246 2 246 3 [kworker/3:1]
root 3963 1 3968 3 qemu-system-x86_64 rhel6u3.img -smp 2 -m 512 -daemonize
由上面的命令行及其输出信息可知,CPU绑定之前,代表这个客户机的QEMU进程和代表各个vCPU的QEMU线程分别被调度到cpu0和cpu1上。使用taskset命令将QEMU进程和第一个vCPU的线程绑定到cpu2,将第二个vCPU线程绑定到cpu3上。绑定之后,即可查看到绑定的结果是生效的,代表两个vCPU的QEMU线程分别运行在cpu2和cpu3上(即使再过一段时间后,它们也不会被调度到其他CPU上去)。
对taskset命令解释一下,此处使用的语法是:taskset -p [mask] pid 。其中,mask是一个代表了处理器亲和性的掩码数字,转化为二进制表示后,它的值从最低位到最高位分别代表了第一个逻辑CPU到最后一个逻辑CPU,进程调度器可能将该进程调度到所有标为“1”的位代表的CPU上去运行。根据上面的输出,taskset运行之前,QEMU线程的处理器亲和性mask值是0x3(其二进制值为:0011),可知其可能会被调度到cpu0和cpu1上运行;而运行“taskset -p 0x4 3967”命令后,提示新的mask值被设为0x4(其二进制值为:0100),所以该进程就只能被调度到cpu2上去运行,即通过taskset工具实现了vCPU进程绑定到特定的CPU上。
上面命令行中,根据ps命令可以看到QEMU的线程和进程的关系,但如何查看vCPU与QEMU线程之间的关系呢?可以切换(“Ctrl+Alt+2”快捷键)到QEMU monitor中进行查看,运行“info cpus”命令即可(还记得3.6节中运行过的“info kvm”命令吧),其输出结果如下:
(qemu) info cpus
* CPU #0: pc=0xffffffff810375ab thread_id=3967
CPU #1: pc=0xffffffff812b2594 thread_id=3968
从上面的输出信息可知,客户机中的cpu0对应的线程ID为3967,cpu1对应的线程ID为3968。另外,“CPU #0”前面有一个星号(*),是标识cpu0是BSP(Boot Strap Processor,系统最初启动时在SMP生效前使用的CPU)。
总的来说,在KVM环境中,一般并不推荐手动地人为设置QEMU进程的处理器亲和性来绑定vCPU,但是,在非常了解系统硬件架构的基础上,根据实际应用的需求,是可以将其绑定到特定的CPU上去从而提高客户机中的CPU执行效率或者实现CPU资源独享的隔离性。
[2013.03.31] 添加几个关于CPU亲和性的小知识点:
1. 限制CPU亲和性的原因一般有如下3个:
1.1 任务中有大量计算存在;
1.2 测试复杂的应用程序(随着CPU个数的正常,程序的处理能力可以线性地扩展);
1.3 运行时间敏感的进程(实时性要求很高)。
2. 子进程会继承父进程的affinity属性(其实用taskset方式启动一个进程就是一次fork+exec)。
3. 在进程的代码中,使用sched_setaffinity函数可以设置该进程的CPU亲和性。
#include
int sched_setaffinity(pid_t pid, unsigned int len, unsigned long *mask);
int sched_getaffinity(pid_t pid, unsigned int len, unsigned long *mask);
4. 使用Nginx时,其配置文件conf/nginx.conf中支持一个名为worker_cpu_affinity的配置项,也就是说,nginx可以为每个工作进程绑定CPU。
如下配置:
worker_processes 3;
worker_cpu_affinity 0010 0100 1000;
这里0010 0100 1000是掩码,分别代表第2、3、4颗CPU核心(或超线程)。
重启nginx后,3个工作进程就可以各自用各自的CPU了。
5. 在Windows系统中的“任务管理器”中,也可以对一个进程设置CPU亲和性“set affinity”。
posted @
2016-07-25 14:33 yuhen 阅读(294) |
评论 (0) |
编辑 收藏首先声明出处:sam的技术bloghttp://blog.sina.com.cn/samzhen1977
1. Linux下,如何看每个CPU的使用率:
#top -d 1
(此时会显示以1s的频率刷新系统负载显示,可以看到总的CPU的负载情况,以及占CPU最高的进程id,进程名字等信息)
(切换按下数字1,则可以在显示多个CPU和总CPU中切换)
之后按下数字1. 则显示多个CPU (top后按1也一样)
Cpu0 : 1.0%us, 3.0%sy, 0.0%ni, 96.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Cpu1 : 0.0%us, 0.0%sy, 0.0%ni,100.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
这里对us,sy,ni,id,wa,hi,si,st进行分别说明:
us 列显示了用户模式下所花费 CPU 时间的百分比。us的值比较高时,说明用户进程消耗的cpu时间多,但是如果长期大于50%,需要考虑优化用户的程序。
sy 列显示了内核进程所花费的cpu时间的百分比。这里us + sy的参考值为80%,如果us+sy 大于 80%说明可能存在CPU不足。
ni 列显示了用户进程空间内改变过优先级的进程占用CPU百分比。
id 列显示了cpu处在空闲状态的时间百分比。
wa 列显示了IO等待所占用的CPU时间的百分比。这里wa的参考值为30%,如果wa超过30%,说明IO等待严重,这可能是磁盘大量随机访问造成的,也可能磁盘或者磁盘访问控制器的带宽瓶颈造成的(主要是块操作)。
hi
si
st
2. 在Linux下,如何确认是多核或多CPU:
#cat /proc/cpuinfo
如果有多个类似以下的项目,则为多核或多CPU:
processor : 0
......
processor : 1
3. 如何察看某个进程在哪个CPU上运行:
#top -d 1
之后按下f.进入top Current Fields设置页面:
选中:j: P = Last used cpu (SMP)
则多了一项:P 显示此进程使用哪个CPU。
Sam经过试验发现:同一个进程,在不同时刻,会使用不同CPU Core.这应该是Linux Kernel SMP处理的。
4. 配置Linux Kernel使之支持多Core:
内核配置期间必须启用 CONFIG_SMP 选项,以使内核感知 SMP。
Processor type and features ---> Symmetric multi-processing support
察看当前Linux Kernel是否支持(或者使用)SMP
#uname -a
5. Kernel 2.6的SMP负载平衡:
在 SMP 系统中创建任务时,这些任务都被放到一个给定的 CPU 运行队列中。通常来说,我们无法知道一个任务何时是短期存在的,何时需要长期运行。因此,最初任务到 CPU 的分配可能并不理想。
为了在 CPU 之间维护任务负载的均衡,任务可以重新进行分发:将任务从负载重的 CPU 上移动到负载轻的 CPU 上。Linux 2.6 版本的调度器使用负载均衡(load balancing) 提供了这种功能。每隔 200ms,处理器都会检查 CPU 的负载是否不均衡;如果不均衡,处理器就会在 CPU 之间进行一次任务均衡操作。
这个过程的一点负面影响是新 CPU 的缓存对于迁移过来的任务来说是冷的(需要将数据读入缓存中)。
记住 CPU 缓存是一个本地(片上)内存,提供了比系统内存更快的访问能力。如果一个任务是在某个 CPU 上执行的,与这个任务有关的数据都会被放到这个 CPU 的本地缓存中,这就称为热的。如果对于某个任务来说,CPU 的本地缓存中没有任何数据,那么这个缓存就称为冷的。
不幸的是,保持 CPU 繁忙会出现 CPU 缓存对于迁移过来的任务为冷的情况。
6. 应用程序如何利用多Core :
开发人员可将可并行的代码写入线程,而这些线程会被SMP操作系统安排并发运行。
另外,Sam设想,对于必须顺序执行的代码。可以将其分为多个节点,每个节点为一个thread.并在节点间放置channel.节点间形如流水线。这样也可以大大增强CPU利用率。
例如:
游戏可以分为3个节点。
1.接受外部信息,声称数据 (1ms)
2.利用数据,物理运算(3ms)
3.将物理运算的结果展示出来。(2ms)
如果线性编程,整个流程需要6ms.
但如果将每个节点作为一个thread。但thread间又同步执行。则整个流程只需要3ms.
posted @
2016-06-22 10:39 yuhen 阅读(277) |
评论 (0) |
编辑 收藏断点设置
gdb断点分类:
以设置断点的命令分类:
breakpoint
可以根据行号、函数、条件生成断点。
watchpoint
监测变量或者表达式的值发生变化时产生断点。
catchpoint
监测信号的产生。例如c++的throw,或者加载库的时候。
gdb中的变量从1开始标号,不同的断点采用变量标号同一管理,可以 用enable、disable等命令管理,同时支持断点范围的操作,比如有些命令接受断点范围作为参数。
例如:disable 5-8
1、break及break变种详解:
相关命令有break,tbreak,rbreak,hbreak,thbreak,后两种是基于硬件的,先不介绍。
>>break 与 tbeak
break,tbreak可以根据行号、函数、条件生成断点。tbreak设置方法与break相同,只不过tbreak只在断点停一次,过后会自动将断点删除,break需要手动控制断点的删除和使能。
break 可带如下参数:
linenum 本地行号,即list命令可见的行号
filename:linenum 制定个文件的行号
function 函数,可以是自定义函数也可是库函数,如open
filename:function 制定文件中的函数
condtion 条件
*address 地址,可是函数,变量的地址,此地址可以通过info add命令得到。
例如:
break 10
break test.c:10
break main
break test.c:main
break system
break open
如果想在指定的地址设置断点,比如在main函数的地址出设断点。
可用info add main 获得main的地址如0x80484624,然后用break *0x80484624.
条件断点就是在如上述指定断点的同时指定进入断点的条件。
例如:(假如有int 类型变量 index)
break 10 if index == 3
tbreak 12 if index == 5
>>rbreak
rbreak 可以跟一个规则表达式。rbreak + 表达式的用法与grep + 表达式相似。即在所有与表达式匹配的函数入口都设置断点。
rbreak list_* 即在所有以 list_ 为开头字符的函数地方都设置断点。
rbreak ^list_ 功能与上同。
>>查看断点信息
info break [break num ]
info break 可列出所有断点信息,info break 后也可设置要查看的break num如:
info break 1 列出断点号是1的断点信息
Num Type Disp Enb Address What
1 breakpoint keep y <MULTIPLE>
stop only if i==1
breakpoint already hit 1 time
1.1 y 0x080486a2 in void foo<int>() at t.cc:8
1.2 y 0x080486ca in void foo<double>() at t.cc:8
posted @
2014-12-12 17:40 yuhen 阅读(1863) |
评论 (0) |
编辑 收藏[原文地址:https://wiki.ubuntu.com/UEFI-howto]
1. Introduction
本文介绍了如何在Ubuntu下建立EDKII编译环境,使用QEMU运行EDKII BIOS.
2. 建立EDKII编译环境
Note: EDKII (12/1/2011 SVN checkout) builds cleanly on 11.10 (with packages in proposed repo installed).
Note: EDKII is known to build correctly on Natty (11.04) but has compilation issues with the more pedantic gcc 4.6.1 ,
so it fails to build on Oneiric (as of 20 Oct 2011). However, upsteam are aware of this and are working on a fix.
(1) Install required packages
sudo apt-get install build-essential subversion uuid-dev iasl
(2) Get the latest source for EDKII
In a suitable working directory extract the latest EDKII source. Note there is no password for guest account, so hit enter.
$ mkdir ~/src $ cd ~/src $ git clone git://github.com/tianocore/edk2.git
(4) Compile base tools
For MS Windows, prebuilt binaries of the base tools are shipped with the source;
on Ubuntu the base tools required for building EDKII need to be built first.
$ cd ~/src $ make -C edk2/BaseTools
(5) Set up build environment
You need to set EDK_TOOLS_PATH and set up the build environment by running the edksetup.sh script provided in the
source. This script will copy template and configuration files to edk2/Conf directory.
$ cd ~/src/edk2 $ export EDK_TOOLS_PATH=$HOME/src/edk2/BaseTools $ . edksetup.sh BaseTools
(6) Set up build target
To set up the build target you need to modify the conf file Conf/target.txt.
This will enable the firmware package to be built and set up the compiler version used.
$ vi ~/src/edk2/Conf/target.txt
Find
ACTIVE_PLATFORM = Nt32Pkg/Nt32Pkg.dsc
and replace it with
ACTIVE_PLATFORM = MdeModulePkg/MdeModulePkg.dsc
Find
TOOL_CHAIN_TAG = MYTOOLS
and replace it with your version on GCC here for example GCC 4.4 will be used.
TOOL_CHAIN_TAG = GCC44
Find
TARGET_ARCH = IA32
and replace it with 'X64' for 64bit or 'IA32 X64' to build both architectures.
TARGET_ARCH = X64
3. 编译MdeModulePkg
This will build the MdeModulePkg and helloworld program that we can use later when we launch the UEFI shell from emulator...
Just type build...
$ cd ~/src/edk2/ $ build
On a Core i5 with 4GB of RAM the total build time is two minutes.
4. Build a full system firmware image (OVMF)
The Open Virtual Machine Firmware (or "OVMF") can be used to enable UEFI within virtual machines.
It provides libraries and drivers related to virtual machines.
Currently OVMF support QEMU for emulating UEFI on IA32 and X86-64 based systems.
You could also build OVMF with source level debugging enabled.
Set up build target
You can build OVMF for IA32 or X64 architechtures.
In this example we will build OVMF for X64 architecture.
You will need to modify Conf/target.txt and replace ACTIVE_PLATFORM with the right dsc file.
$ vi ~/src/edk2/Conf/target.txt
Find
ACTIVE_PLATFORM = MdeModulePkg/MdeModulePkg.dsc
replace with
ACTIVE_PLATFORM = OvmfPkg/OvmfPkgX64.dsc
This will set the Target Arch to X64, PEI code to X64 and DXE/UEFI code to X64.
Build the OvmfPkg
$ cd ~/src/edk2 $ build
On an i5 with 4GB RAM the total build time is less than two minutes. The files built will be located
under ~/src/Build/
Building the OvmfPkg with Secure Boot support
If you wish to build OVMF with Secure Boot, you must follow the openssl installation instructions
found in:-
~/src/edk2/CryptoPkg/Library/OpensslLib/Patch-HOWTO.txt
and build like this instead:-
$ cd ~/src/edk2 $ build –D SECURE_BOOT_ENABLE
If you see an error that "the required fv image size exceeds the set fv image size" consult this mailing list post.
But note that the rest of this guide currently assumes you build WITHOUT Secure Boot.
5. Running UEFI in QEMU
$ sudo apt-get install qemu
Initial setup
create a directory where you will set up firmware, a directory to use as hard disk image for QEMU.
$ mkdir ~/ovmf-qemu $ cd ~/ovmf-qemu $ mkdir hda-contents
Copy the firmware to your working directory.
$ cd ~/ovmf-qemu $ cp ~/src/edk2/Build/OvmfX64/DEBUG_GCC45/FV/OVMF.fd ./bios.bin $ cp ~/src/edk2/Build/OvmfX64/DEBUG_GCC45/FV/OvmfVideo.rom ./vgabios-cirrus.bin
Run UEFI image in QEMU
This will launch UEFI firmware image on QEMU and drop to UEFI shell.
You can type exit and get to the UEFI menus or work with the shell.
Note: to release mouse grab from QEMU hit CTRL+ALT
$ qemu-system-x86_64 -L . -hda fat:hda-contents
6. Running HelloWorld.efi
As part of the MdeModule build, you also built a HelloWorld.efi. Exit any QEMU sessions you are running and copy the hello world program to your QEMU hard disk.
$ cp ~/src/edk2/Build/MdeModule/DEBUG_GCC45/X64/HelloWorld.efi ~/ovmf-qemu/hda-contents/.
Launch UEFI firmware in QEMU, and run the hello world program.
7. 在QEMU上利用OVMF启动Ubuntu 12.04
You can boot the Ubuntu live CD image using OVMF as your firmware. Please note that splash screen does not work, and you might not be able to get a network connection, but the OS will boot and will be fully functional. I have precise-desktop-amd64.iso downloaded to ~/Downloads/iso/12.04/, I change directory to where I copied the firmware I built and run QEMU with the following options.
$ cd ~/ovmf-qemu $ qemu-system-x86_64 -L . -m 1024 -cdrom ~/Downloads/iso/12.04/precise-desktop-amd64.iso -vga cirrus -enable-kvm
posted @
2014-09-25 14:18 yuhen 阅读(3621) |
评论 (0) |
编辑 收藏1. TCG简单介绍
TCG(Tiny Code Generator)最早被用于C编译器的后端。在TCG相关的代码中,target指的是我们通常说的host,这一点需要注意,并不是我们理解的被仿真的平台。
2. TCG动态翻译技术的几个概念
(1)与dyngen一样,TCG的“function”与qemu的TBs(Translated Block)相对应,即以分支跳转指令结束的代码段。
(2)TCG中有三种变量:temporary, local temporary, global。这三种变量有着不同的生命周期,temporary变量的声明周期是TBs,local temporary变量的声明周期是functions,global变量的声明周期是所有的functions,类似C语言的全局变量。temporary和local temporary变量通常在function内定义,global变量通常在function外定义。全局变量通常被映射到某个内存地址或某个固定的寄存器。
3. TCG operations
就像dyngen动态翻译技术中的micro-operations一样,TCG也采用中间表示的形式(TCG instructions),TCG至中间表示支持的三种变量有两种数据类型:32 bit整型和64 bit整型。另外,指针类型被实现为整型的别名。
TCG指令有固定的形式:
TCG 操作码 输出变量域,输入变量域,常量域
比较特殊的是call指令,其后只跟一个变量,同时作为输出和输入变量域。
举个例子:
add_i32 t0, t1, t2 (t0 <- t1 + t2)
操作码 输出变量域 输入变量域 常量域(输入)
4. TCG是qemu的核心,主要实现了以下翻译流程:
guest binary instructions -> TCG IR -> host binary instructions TCG 定义了一组IR(intermediate representation),这些IR大致可以分为以下几类:
- Mov类操作: mov, movi, ...
- 逻辑操作: and, or, xor, shl, shr, ...
- 算术操作: add, sub, mul, div, ...
- 分支跳转操作: jmp, br, brcond
- 函数调用: call - 内存操作: ld, st
- QEMU的特殊操作: tb_exit, goto_tb, qemu_ld/qemu_st
这里仅对TCG中间表示做一下简单分类,至于每条TCG指令的具体用法,参见qemu源码tcg/readme。
5. TCG 动态翻译过程
前面也提到TCG主要实现以下翻译过程:
guest binary instructions -> TCG IR -> host binary instructions
在qemu源码中,target-ARCH/* 定义了如何将guest binary instructions 反汇编成 TCG IR,tcg/ARCH 定义了如何將 TCG IR 翻译成 host binary instructions。
在下一篇文章中,将会从qemu源码的角度详细分析x86-->x86平台的TCG动态翻译技术的执行过程。
posted @
2014-09-11 10:50 yuhen 阅读(1610) |
评论 (0) |
编辑 收藏 由于刚刚接触qemu,所以前面几篇文章仅仅是肤浅的介绍qemu的一些背景知识,今天突然感觉前面说的太没有条理了,而且大部分是读别人的文章,一知半解,没有自己的总结体会,今天感觉稍微有点心得,敬请指教。
1. 明确guest和host
对于qemu而言,被仿真的平台成为guest或者说target;很明显,运行qemu的平台就称为host。
2. 了解qemu动态翻译技术的发展
qemu运用动态翻译的技术将guest binary instructions动态翻译成host binary instructions,之后由host运行翻译后的指令。在qemu-0.9之前的版本都采用dyngen的动态翻译技术,而从qemu-0.10开始的版本开始采用TCG(Tiny Code Generator)的翻译技术。
采用dyngen 动态翻译技术的资料主要有以下两篇文章,是了解动态翻译技术入门的好文章(在后续的分析中,会简单介绍dyngen技术):
介绍TCG技术的文章则相对较少,主要是阅读qemu源码和qemu官网上的相关资料。
3. dyngen简单介绍
图1简单说明了qemu采用dyngen动态翻译技术将目标平台指令翻译成主机平台指令的简单过程。
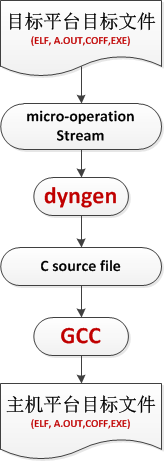
假设target为PowerPC,host为x86,说明整个翻译过程:

- <pre style="BACKGROUND-COLOR: #f0f0f0; MARGIN: 4px 0px" class="html" name="code"><pre class="html" name="code"><pre></pre>
- <pre></pre>
- <pre></pre>
- <pre></pre>
- <pre></pre>
- <pre></pre>
- <pre></pre>
- <pre></pre>
- <pre></pre>
- <pre></pre>
- <pre></pre>
- <pre></pre>
- <pre></pre>
- <pre></pre>
- <pre></pre>
- <pre></pre>
- <pre></pre>
- </pre></pre>
dyngen在整个过程中扮演了非常重要的角色,其详细功能在这里不再详述,但是有一个疑问,希望与大家讨论:
在将目标平台指令集向micro-operations这一步的转化中,《QEMU, a Fast and Portable Dynamic Translator》一文中提到采用了hand coded code的方式,我理解是我们说的“硬编码”,即目标平台指令到micro-op是预先写好的一一映射的关系,我的疑问就是这种一一映射的关系是怎么实现的,因为没有看过qemu-0.9之前版本的代码,所以很想知道是怎么hand coded 的。另外,该文还提到“When QEMU first encounters a piece of target code, it translates it to host code ... ....”, 我的问题是qemu怎么处理目标平台的objective file的, 比方说qemu怎么分析一个ELF文件,怎么从中读取指令,怎么来进行后面的hand coded ????
在dyngen动态翻译技术中,还涉及到几个比较重要的地方,比如:
(1)TBs,Translated Blocks
qemu将TB定义为碰到下一个jump指令或修改CPU state的指令之前的所有代码称为一个TB
(2)寄存器分配
target平台的寄存器被映射到host的固定寄存器或指定的内存地址
(3)条件代码的优化
(4)TB块以hash表的形式组织
(5)mmap()系统调用仿真target的MMU
(6)longjmp()实现异常仿真
(7)异步轮询的方式实现中断的仿真
至于(3)~(7)的具体实现方式,现在还比较模糊,希望与大家交流!!!!!!!!!
posted @
2014-09-11 10:49 yuhen 阅读(1265) |
评论 (0) |
编辑 收藏为了更容易理解动态翻译技术,我们暂时忽略掉qemu的其他模块,如用户交互模块,硬件模拟等模块,而是从数据结构的设计,数据结构之间的操作及其应用等方面来进行详细地分析,重点关注动态翻译器和微操作库(micro-ops library)的原理,至于细节的东西可以放在以后去深入分析。
qemu利用了一种可移植的动态代码翻译器以快速地完成客户代码的仿真。qemu本身并不能识别它主机体系结构的指令集,作为替代,每一个客户机指定一个c语言实现的微操作库以及一个客户机代码反汇编器和翻译器,用来将客户代码转换成微操作表,这些微操作可以被认为是一种虚拟机,尽管仅仅是对客户系统模拟的一种优化而已。另外,这些操作本身包括寄存器转化,显示的条件代码更新代码,按位操作,整型和浮点型数学函数,内存加载和存储操作等。
2.1 翻译
2.1.1 基本块的翻译
图1描述了一小段带条件跳转x86代码以及其对应的微操作指令表示,每一条op_开头的微操作指令都将被拷贝到翻译缓冲区中,微操作指令中看起来像参数的常量被称为折叠常量(const folding),在2.3.4接将会进行详细的解释,现在只要把它看成是qemu中定义的微操作指令的参数就可以了。微操作指令的参数中,tb是比较特殊的,它指向与当前翻译缓冲区相关的元数据。另外,JNZ指令对应的微操作指令看起来比较怪异,控制流处理相关的细节将会在2.2.3节和2.2.4节详细介绍。

2.1.2 同步的错误安全舱口
严格的按照“基本块”(basic block)的方式译码将会使得翻译缓冲区中包含一条或多条客户机指令,同时几乎每一条指令都可能产生同步的fault(比方说MMU fault)。为了便于理解,在翻译的时候我们重点考虑比较直接的客户机控制流(比方说,分支跳转:条件跳转和非条件跳转),毕竟,同步的错误(fault)很少出现。对于同步错误(fault)需要一种恢复机制,用来处理翻译缓冲区中的fault。qemu使用longjmp()从翻译缓冲区中跳到仿真器核心代码中。这里描述的意思是:当在执行翻译缓冲区的代码时,遇到了fault,就需要将执行路径切换到qemu的代码中,另外,当qemu处理完fault后,会重新创建一个翻译缓冲区。
2.1 翻译缓冲区的高超技巧
qemu采用了一些不同寻常的技巧来提高性能:
- 冗长的、额外开销大的主机操作(如仿真客户的MMU操作)并不会被直接放进翻译缓冲区,而是以可以从微操作中调用的帮助函数的形式存在
- 一方面减少了对翻译缓冲区的占用,另一方面简化了翻译的过程(qemu中事先保存某些固定指令的翻译结果,当动态翻译器碰到这些指令时,直接跳过去执行就行了)
- 翻译后的微操作指令序列的优化
- 启发式的译码和翻译
2.2.1 通过函数调用来达到节省翻译缓冲区的技术
目前操作系统中的MMU操作指令自身非常复杂。对于MMU操作会产生大量的访存操作,通常的解决方法是增加一个cache,但这进一步增加代码的复杂度。如果将每一次访存操作的这些复杂代码都放入翻译缓冲区中,其代价将会非常的昂贵。除了MMU操作指令,一些特殊的客户机指令也是非常复杂的,如CPUID指令,即使在简化的qemu的实现中,一条x86的CPUID指令都需要75行C代码来实现。与ARPL指令相比,CPUID对于不同的寄存器内容将会表现是完全不同的行为,因此,必须需要一大串冗长的微操作指令来实现CPUID的功能。
为了优化这种代价昂贵,需要冗长的微操作指令来实现的客户机指令,qemu采用能够实现类似函数调用功能的微操作指令的机制来实现,比如ldl_kernel,实现了内核模式的大量数据的读功能;helper_cpuid,这个微操作包含了CPUID指令的实现。
2.2.2 惰性赋值
每一条指令都会隐含性修改指令指针(EIP),并且每一条指令都会修改处理器条件码(比如零标志位,溢出标志位、进位标志位等),但实际的情况是,只要指令按照正确的顺序执行,其实客户代码很少去关心这些状态的变化。对于这些条件码除了条件跳转状态位外,我们很少去关注其他的状态位。图1中一段小小的客户代码都会引起指令指针的修改和条件码修改的大量操作:
- ADDL操作会修改条件码的零和进位/借位标志位
- SUBL操作会修改条件码的零和进位/借位标志位
- ADDL和SUBL都会修改EIP,使其指向下一条指令
由于qemu是按照“基本代码块”为单位进行翻译的,所以只有在整个“基本代码块”翻译完成或显示的读取EIP的时候才会对EIP进行更新,这就避免了EIP的频繁更新的问题。在实际情况下,ADDL和SUBL都不会去读指令指针EIP,因此,可以优化掉翻译后的微操作指令中对EIP更新的微操作,具体描述如图2所示。图2中仅仅是在每个“基本代码块”的最后通过op_jmp_im微操作来进行EIP的更新,即每个“基本代码块”只做一次更新操作。

posted @
2014-09-11 10:48 yuhen 阅读(1412) |
评论 (0) |
编辑 收藏从QEMU-0.10.0开始,TCG成为QEMU新的翻译引擎,使QEMU不再依赖于GCC3.X版本,并且做到了“真正”的动态翻译(从某种意义上说,旧版本是从编译后的目标文件中复制二进制指令)。TCG的全称为“Tiny Code Generator”,QEMU的作者Fabrice Bellard在TCG的说明文件中写到,TCG起源于一个C编译器后端,后来被简化为QEMU的动态代码生成器(Fabrice Bellard以前还写过一个很牛的编译器TinyCC)。实际上TCG的作用也和一个真正的编译器后端一样,主要负责分析、优化Target代码以及生成Host代码。
Target指令 ----> TCG ----> Host指令
以下的讲述以X86平台为例(Host和Target都是X86)。
我在上篇文章中讲到,动态翻译的基本思想就是把每一条Target指令切分成为若干条微指令,每条微指令由一段简单的C代码来实现,运行时通过一个动态代码生成器把这些微指令组合成一个函数,最后执行这个函数,就相当于执行了一条Target指令。
这种思想的基础是因为CPU指令都是很规则的,每条指令的长度、操作码、操作数都有固定格式,根据前面就可推导出后面,所以只需通过反汇编引擎分析出指令的操作码、输入参数、输出参数等,剩下的工作就是编码为目标指令了。
那么现在的CPU指令这么多,怎么知道要分为哪些微指令呢?其实CPU指令看似名目繁多,异常复杂,实际上多数指令不外乎以下几大类:
数据传送、算术运算、逻辑运算、程序控制;
例如,数据传送包括:传送指令(如MOV)、堆栈操作(PUSH、POP)等
程序控制包括:函数调用(CALL)、转移指令(JMP)等;
基于此,TCG就把微指令按以上几大类定义(见tcg/i386/tcg-target.c),例如:其中一个最简单的函数 tcg_out_movi 如下:
// tcg/tcg.c
static inline void tcg_out8(TCGContext *s, uint8_t v)
{
*s->code_ptr++ = v;
}
static inline void tcg_out32(TCGContext *s, uint32_t v)
{
*(uint32_t *)s->code_ptr = v;
s->code_ptr += 4;
}
// tcg/i386/tcg-target.c
static inline void tcg_out_movi(TCGContext *s, TCGType type,
int ret, int32_t arg)
{
if (arg == 0) {
/* xor r0,r0 */
tcg_out_modrm(s, 0x01 | (ARITH_XOR << 3), ret, ret);
} else {
tcg_out8(s, 0xb8 + ret); // 输出操作码,ret是寄存器索引
tcg_out32(s, arg); // 输出操作数
}
}
0xb8 - 0xbf 正是x86指令中的 mov R, Iv 系列操作的16进制码,所以,tcg_out_movi 的功能就是输出 mov 操作的指令码到缓冲区中。可以看出,TCG在生成目标指令的过程中是采用硬编码的,因此,要让TCG运行在不同的Host平台上,就必须为不同的平台编写微操作函数。
接下来,我还是以一条Target指令 jmp f000:e05b 来讲述它是如何被翻译成Host指令的。其中几个关键变量的定义如下:
gen_opc_buf: 操作码缓冲区
gen_opparam_buf:参数缓冲区
gen_code_buf: 存放翻译后指令的缓冲区
gen_opc_ptr、gen_opparam_ptr、gen_code_ptr三个指针变量分别指向上述缓冲区。
jmp f000:e05b 的编码是:EA 5B E0 00 F0,
首先是disas_insn()函数翻译指令,当碰到第1个字节EA,分析可知这是一条16位无条件跳转指令,因此依次从后续字节中得到offset和selector,然后分为如下微指令操作:
gen_op_movl_T0_im(selector);
gen_op_movl_T1_imu(offset);
gen_op_movl_seg_T0_vm(R_CS);
gen_op_movl_T0_T1();
gen_op_jmp_T0();
这几个微指令函数的定义如下(功能可看注释):
static inline void gen_op_movl_T0_im(int32_t val)
{
tcg_gen_movi_tl(cpu_T[0], val); // 相当于 cpu_T[0] = val
}
static inline void gen_op_movl_T1_imu(uint32_t val)
{
tcg_gen_movi_tl(cpu_T[1], val); // 相当于 cpu_T[1] = val
}
static inline void gen_op_movl_seg_T0_vm(int seg_reg)
{
tcg_gen_andi_tl(cpu_T[0], cpu_T[0], 0xffff); // cpu_T[0] = cpu_T[0]&0xffff
tcg_gen_st32_tl(cpu_T[0], cpu_env,
offsetof(CPUX86State,segs[seg_reg].selector)); // the value of cpu_T[0] store to the 'offset' of cpu_env
tcg_gen_shli_tl(cpu_T[0], cpu_T[0], 4); // cpu_T[0] = cpu_T[0]<<4
tcg_gen_st_tl(cpu_T[0], cpu_env,
offsetof(CPUX86State,segs[seg_reg].base)); // the value of cpu_T[0] store to the 'offset' of cpu_env
}
static inline void gen_op_movl_T0_T1(void)
{
tcg_gen_mov_tl(cpu_T[0], cpu_T[1]); // cpu_T[0] = cpu_T[1]
}
static inline void gen_op_jmp_T0(void)
{
tcg_gen_st_tl(cpu_T[0], cpu_env, offsetof(CPUState, eip)); // // the value of cpu_T[0] store to the 'offset' of cpu_env
}
其中,cpu_T[0]、cpu_T[1]和前面讲过的T0、T1功能一样,都是用来临时存储的变量。在32位目标机上,tcg_gen_movi_tl 就是 tcg_gen_op2i_i32 函数,它的定义如下:
static inline void tcg_gen_op2i_i32(int opc, TCGv_i32 arg1, TCGArg arg2)
{
*gen_opc_ptr++ = opc;
*gen_opparam_ptr++ = GET_TCGV_I32(arg1);
*gen_opparam_ptr++ = arg2;
}
static inline void tcg_gen_movi_i32(TCGv_i32 ret, int32_t arg)
{
tcg_gen_op2i_i32(INDEX_op_movi_i32, ret, arg);
}
gen_opparam_buf 是用来存放操作数的缓冲区,它的存放顺序是:第1个4字节代表s->temps(用来存放目标值的数组,即输出参数)的索引,第2个4字节及之后字节代表输入参数,对它的具体解析过程可见 tcg_reg_alloc_movi 函数,示例代码如下:
TCGTemp *ots;
tcg_target_ulong val;
ots = &s->temps[args[0]];
val = args[1];
ots->val_type = TEMP_VAL_CONST;
ots->val = val; // 把输入值暂时存放在ots结构中
接下来,根据 gen_opc_buf 保存的操作码列表,gen_opparam_buf 保存的参数列表,以及TCGContext结构,经过 tcg_gen_code_common 函数调用,jmp f000:e05b 生成的最终指令如下:
099D0040 B8 00 F0 00 00 mov eax,0F000h
099D0045 81 E0 FF FF 00 00 and eax,0FFFFh
099D004B 89 45 50 mov dword ptr [ebp+50h],eax
099D004E C1 E0 04 shl eax,4
099D0051 89 45 54 mov dword ptr [ebp+54h],eax
099D0054 B8 5B E0 00 00 mov eax,0E05Bh
099D0059 89 45 20 mov dword ptr [ebp+20h],eax
099D005C 31 C0 xor eax,eax
099D005E E9 25 5D CA 06 jmp _code_gen_prologue+8 (10675D88h) /* 返回 */
从上面可以看出,生成的Host代码很简洁,对于Target机的JMP,Host没有去执行真正的跳转指令,而只是简单的将目标地址放到EIP中而已。
QEMU维护着一个称为 CPUState 的数据结构,这个结构包括了Target机CPU的所有寄存器,像EAX,EBP,ESP,CS,EIP,EFLAGS等。
它总是代表着Target机的当前状态,我用env变量来表示 CPUState 结构,
QEMU每次解析Target指令时,总是以 env.cs+env.eip 为开始地址的。
像上面说的jmp f000:e05b指令,它分解为如下微操作:
gen_op_movl_T0_im(selector);
gen_op_movl_T1_imu(offset);
gen_op_movl_seg_T0_vm(R_CS);
gen_op_movl_T0_T1();
gen_op_jmp_T0();
这几条微操作的意义概括起来很简单,就是把selector放到env.cs,把offset放到env.eip。在调试中,把QEMU执行Target指令的过程和Bochs比较是一件很有趣的事情,当然,这只是设计理念的不同,而并没有技术上的优劣之分。
posted @
2014-09-11 10:48 yuhen 阅读(1916) |
评论 (0) |
编辑 收藏1 qemu概述
qemu是一种快速的多体系结构仿真器,通过动态翻译的技术达到了优异的仿真速度。目前,qemu支持两种操作模式:
- 全系统仿真模式。在这种模式下,qemu完整的仿真目标平台,此时,qemu就相当于一台完整的pc机,例如包括一个或多个处理器以及各种外围设备。这种模式可以用来运行不同的操作系统或调试操作系统的代码。
- 用户态仿真模式。在这种模式下,qemu能够运行不同于主机平台的其他平台的程序(比如,在x86平台上运行为arm平台编译的程序),其中典型的代表wine windows API emulator。另外,在这种模式下能够进行方便的交叉编译和调试。
对于全系统仿真模式,qemu目前可以支持的硬件列表如下:
- x86 or x86_64 体系结构处理器
- ISA PC (没有PCI总线的PC)
- PowerPC 处理器
- 32/64bit的SPARC 处理器
- 32/64bit的MIPS处理器
- ARM体系结构的处理器
- PXA 270、PXA 255
- OMAP 310、OMAP 2420、OMAP 310
对于用户态仿真模式,qemu支持的硬件列表如下:x86 (32 and 64 bit), PowerPC (32 and 64 bit), ARM, MIPS (32 bit only), Sparc (32 and 64 bit), Alpha, ColdFire(m68k), CRISv32 and MicroBlaze CPUs are supported.
1.1 qemu 的本质
众所周知,Bochs 是一款可移植的IA-32仿真器,它利用模拟的技术来仿真目标系统,具体来说,将是将目标系统的指令分解,然后模拟分解后的指令以达到同样的效果。这种方法将每一条目标指令分解成多条主机系统的指令,很明显会大大降低仿真的速度。
qemu则是采用动态翻译的技术,先将目标代码翻译成一系列等价的被称为“微操作”(micro-operations)的指令,然后再对这些指令进行拷贝,修改,连接,最后产生一块本地代码。这些微操作排列复杂,从简单的寄存器转换模拟到整数/浮点数学函数模拟再到load/store操作模拟,其中load/store操作的模拟需要目标操作系统分页机制的支持。
qemu对客户代码的翻译是按块进行的,并且翻译后的代码被缓存起来以便将来重用。在没有中断的情况下,翻译后的代码仅仅是被链接到一个全局的链表上,目的是保证整个控制流保持在目标代码中,当异步的中断产生时,中断处理函数就会遍历串连翻译后代码的全局链表来在主机上执行翻译后的代码,这就保证了控制流从目标代码跳转到qemu代码。简单概括下:指定某个中断来控制翻译代码的执行,即每当产生这个中断时才会去执行翻译后的代码,没有中断时仅仅只是个翻译过程而已。这样做的好处就是,代码是是按块翻译,按块执行的,不像Bochs翻译一条指令,马上就执行一条指令。
1.2 qemu能够模拟的硬件
Bochs和qemu从非常低的层次对硬件进行模拟,对于像总线和外围设备如显卡,网卡,磁盘控制器等都有相对应的软件的表示,但是二者仅对有限的硬件集合进行精确的模拟,比如对中断控制器,总线驱动,磁盘驱动,键盘,鼠标,显卡以及网卡的模拟。随着时间的推移,可模拟的硬件集合将会扩展到客户操作系统能够支持的尽可能多的设备。Qemu和Bochs都利用运行在模拟机中的BIOSes来初始化硬件的某些部分,这种设计思想使得对设备的仿真忠于原始的硬件。
除了模拟之外,设备驱动利用主机的功能来提供模拟和用户要求的功能,下面来看几个例子:
- 帧缓冲区通过用户可选择的接口被暴露出来,对于qemu来说,帧缓冲有SDL window,VNC Server和无图形界面的输出三个可供选择的选项
- qemu中的网络可以是被禁止的,可以是被桥接到主机的,可以使用虚拟以太网协议创建的Unix套接字,还可以是被在qemu中被完全模拟的
1.3 可移植性
qemu采用了模块化的设计思想,仿真器中与目标平台相关的部分被分离到它们自己的文件和目录中。对于核心部分,驱动部分和动态翻译器来说,所有目标平台都声明相同的接口,在整个qemu的111,000行代码中,目标平台相关的组件代码大约占了1/3,特别地,x86目标平台的大约不超过8000行。与Bochs不同的是,qemu对目标平台的描述非常的紧凑,因此,可以模拟大量的目标平台。
qemu要求公开有关编译执行的信息以便动态翻译器使用,幸运地是,这些信息中的绝大部分对于调试器,动态连接器和单独编译来说都是非常必要的。另外,qemu完全由C语言编写,在主机和目标平台环境之间创建了一个隔离层。值得一提的是动态翻译器使用了带GNU扩展的C编写,这种结构化的可移植性,再加上GCC对大量系统的支持,使得qemu在主机系统之间的可移植性大大增加。
本文仅仅简单介绍下了qemu的相关知识,下一篇文章将会深入分析qemu的实现原理。
posted @
2014-09-11 10:47 yuhen 阅读(1313) |
评论 (0) |
编辑 收藏