由于刚刚接触qemu,所以前面几篇文章仅仅是肤浅的介绍qemu的一些背景知识,今天突然感觉前面说的太没有条理了,而且大部分是读别人的文章,一知半解,没有自己的总结体会,今天感觉稍微有点心得,敬请指教。
1. 明确guest和host
对于qemu而言,被仿真的平台成为guest或者说target;很明显,运行qemu的平台就称为host。
2. 了解qemu动态翻译技术的发展
qemu运用动态翻译的技术将guest binary instructions动态翻译成host binary instructions,之后由host运行翻译后的指令。在qemu-0.9之前的版本都采用dyngen的动态翻译技术,而从qemu-0.10开始的版本开始采用TCG(Tiny Code Generator)的翻译技术。
采用dyngen 动态翻译技术的资料主要有以下两篇文章,是了解动态翻译技术入门的好文章(在后续的分析中,会简单介绍dyngen技术):
介绍TCG技术的文章则相对较少,主要是阅读qemu源码和qemu官网上的相关资料。
3. dyngen简单介绍
图1简单说明了qemu采用dyngen动态翻译技术将目标平台指令翻译成主机平台指令的简单过程。
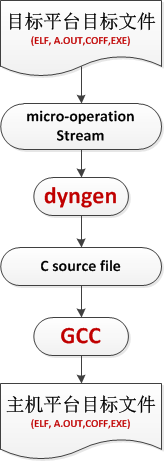
假设target为PowerPC,host为x86,说明整个翻译过程:

- <pre style="BACKGROUND-COLOR: #f0f0f0; MARGIN: 4px 0px" class="html" name="code"><pre class="html" name="code"><pre></pre>
- <pre></pre>
- <pre></pre>
- <pre></pre>
- <pre></pre>
- <pre></pre>
- <pre></pre>
- <pre></pre>
- <pre></pre>
- <pre></pre>
- <pre></pre>
- <pre></pre>
- <pre></pre>
- <pre></pre>
- <pre></pre>
- <pre></pre>
- <pre></pre>
- </pre></pre>
dyngen在整个过程中扮演了非常重要的角色,其详细功能在这里不再详述,但是有一个疑问,希望与大家讨论:
在将目标平台指令集向micro-operations这一步的转化中,《QEMU, a Fast and Portable Dynamic Translator》一文中提到采用了hand coded code的方式,我理解是我们说的“硬编码”,即目标平台指令到micro-op是预先写好的一一映射的关系,我的疑问就是这种一一映射的关系是怎么实现的,因为没有看过qemu-0.9之前版本的代码,所以很想知道是怎么hand coded 的。另外,该文还提到“When QEMU first encounters a piece of target code, it translates it to host code ... ....”, 我的问题是qemu怎么处理目标平台的objective file的, 比方说qemu怎么分析一个ELF文件,怎么从中读取指令,怎么来进行后面的hand coded ????
在dyngen动态翻译技术中,还涉及到几个比较重要的地方,比如:
(1)TBs,Translated Blocks
qemu将TB定义为碰到下一个jump指令或修改CPU state的指令之前的所有代码称为一个TB
(2)寄存器分配
target平台的寄存器被映射到host的固定寄存器或指定的内存地址
(3)条件代码的优化
(4)TB块以hash表的形式组织
(5)mmap()系统调用仿真target的MMU
(6)longjmp()实现异常仿真
(7)异步轮询的方式实现中断的仿真
至于(3)~(7)的具体实现方式,现在还比较模糊,希望与大家交流!!!!!!!!!
posted on 2014-09-11 10:49
yuhen 阅读(1344)
评论(0) 编辑 收藏 引用 所属分类:
技术文档