工具:Wireshark(Windows或Linux),tcpdump(Linux)
要求:使用过滤器捕获特定分组;用脚本分析大量流量数据(建议用perl)。
内容:Web流量分析
清除本机DNS缓存(ipconfig /flushdns),访问某一网站主页,捕获访问过程中的所有分组,分析并回答下列问题:
(1)简述访问web页面的过程。
(2)找出DNS解析请求、应答相关分组,传输层使用了何种协议,端口号是多少?所请求域名的IP地址是什么?
(3)统计访问该页面共有多少请求IP分组,多少响应IP分组?(提示:用脚本编程实现)
(4)找到TCP连接建立的三次握手过程,并结合数据,绘出TCP连接建立的完整过程,注明每个TCP报文段的序号、确认号、以及SYN\ACK的设置。
(5)针对(4))中的TCP连接,该TCP连接的四元组是什么?双方协商的起始序号是什么?TCP连接建立的过程中,第三次握手是否带有数据?是否消耗了一个序号?
(6)找到TCP连接的释放过程,绘出TCP连接释放的完整过程,注明每个TCP报文段的序号、确认号、以及FIN\ACK的设置。
(7)针对(6)中的TCP连接释放,请问释放请求由服务器还是客户发起?FIN报文段是否携带数据,是否消耗一个序号?FIN报文段的序号是什么?为什么是这个值?
(8)在该TCP连接的数据传输过程中,找出每一个ACK报文段与相应数据报文段的对应关系,计算这些数据报文段的往返时延RTT(即RTT样本值)。根据课本200页5.6.2节内容,给每一个数据报文段估算超时时间RTO。(提示:用脚本编程实现)
(9)分别找出一个HTTP请求和响应分组,分析其报文格式。参照课本243页图6-12,在截图中标明各个字段。
(11)请描述HTTP协议的持续连接的两种工作方式。访问这些页面(同一网站的不同页面)的过程中,采用了哪种方式?
wireshark简介
什么是Wireshark
Wireshark是网络包分析工具。网络包分析工具的主要作用是尝试捕获网络包,并尝试显示包的尽可能详细的情况。
你可以把网络包分析工具当成是一种用来测量有什么东西从网线上进出的测量工具,就好像使电工用来测量进入电信的电量的电度表一样。(当然比那个更高级)过去的此类工具要么是过于昂贵,要么是属于某人私有,或者是二者兼顾。Wireshark出现以后,这种现状得以改变。
Wireshark可能算得上是今天能使用的最好的开源网络分析软件。
主要应用
下面是Wireshark一些应用的举例:
• 网络管理员用来解决网络问题
• 网络安全工程师用来检测安全隐患
• 开发人员用来测试协议执行情况
• 用来学习网络协议
除了上面提到的,Wireshark还可以用在其它许多场合。
wireshark界面如下所示:

在capture部分选择网卡,然后点击start就开始捕获数据,然后打开浏览器访问某个网页,即可获得大量数据包。 也可以通过菜单栏Capture——Interfaces对话框开始。
两个不错的教程下载地址:http://down.51cto.com/data/626380
http://down.51cto.com/data/626381
设计与实现过程
(1)简述访问web页面的过程,以西邮主页为例:
a)浏览器向DNS请求解析www.xupt.edu.cn的IP地址
b)域名系统DNS解析出邮电大学的IP地址202.117.128.8
c)浏览器与服务器建立TCP连接
d)浏览器发出取文件命令
e)服务器端给出响应,把首页文件发送给浏览器
f)释放TCP连接
g)浏览器显示西安邮电大学首页中的所有文本
(2)wireshark中DNS分组默认使用浅蓝色

DNS解析请求分组,由下图可以看出DNS是基于UDP的,源端口号1051,目的端口号53:
DNS应答分组,源端口号53,目的端口号1051:
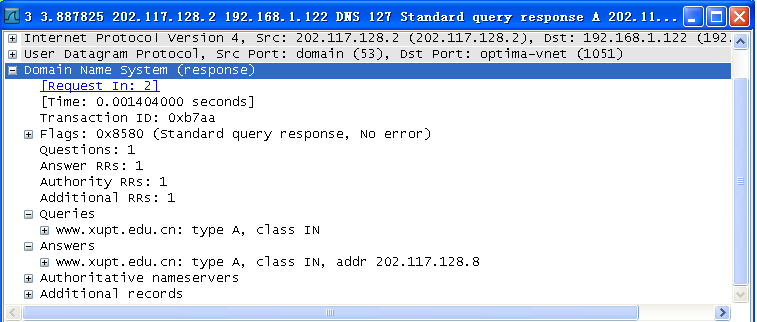
如上所示,传输层使用了UDP(User Datagram protocol)协议。
请求域名的IP地址为:202.117.128.8
(3)应用如下显示过滤规则,对包进行过滤:

然后点击菜单栏的statics,接着点击summary选项,然后就能看到过滤后显示的包的各项统计数据:

由上图知63个IP请求分组(Display部分traffic,共捕获155个包,显示的为63个)
脚本实现:
- #!/usr/bin/perl
- $i=0;
- while(<>){
- if(/Frame/){
- $i++;
- }
- }
- print "The number of IP request packets is:",$i,"\n";

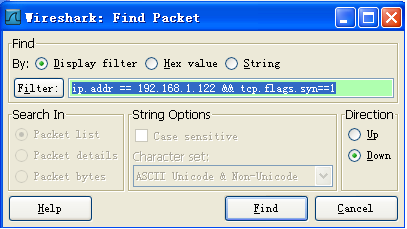
(4)比较重要的TCP三次握手问题,首先按下图方法(edit——find packet)查找到请求连接的包,(捕获的包少的话,直接观察查找就行)

第一次握手:序号:seq=0;无确认号;ACK=0(not set);SYN=1

第二次握手:序号:seq=0;确认号:ack=1;ACK=1;SYN=1

第三次握手:序号seq=1;确认号:ack=1;ACK=1;SYN=0(not set);
还有一张画的略挫的图:

(5)四元组:源IP地址:192.168.1.122、源端口号:1115;
目的IP地址:202.117.128.8、目的端口号:80
由上题知,双方协商的起始序号是0。
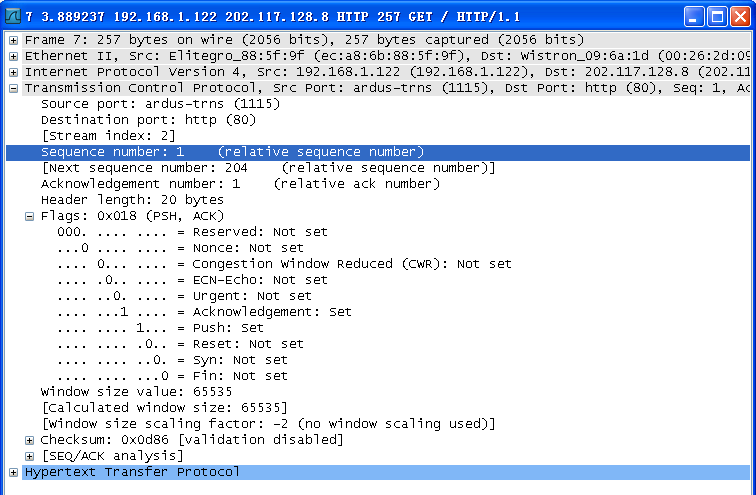
由上图,第三次握手后的报文段。序号seq:=1和第三次握手报文中的序号相同,由此可以看出第三次报文没有消耗序号,没有带数据。
(6)比较重要的TCP四次挥手释放链接
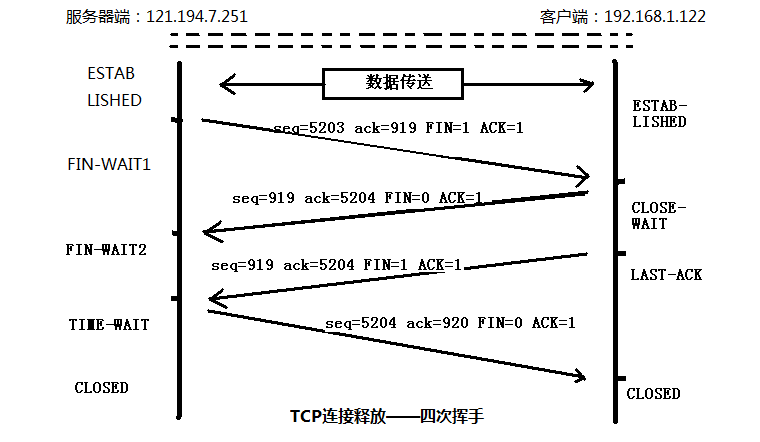
使用显示过滤规则选择一个客户端端口(打开一个网页其实会建立许多TCP连接,选择一个端口也是选择一个特定的TCP连接):tcp.port == 2088 得到下面这些报文
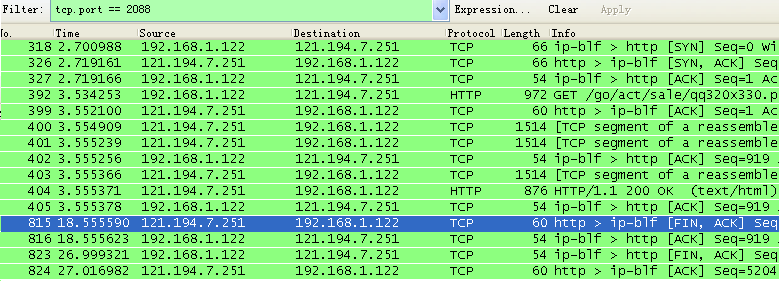

第一次挥手。序号:seq=5203、确认号:ack=919、FIN=1、ACK=1
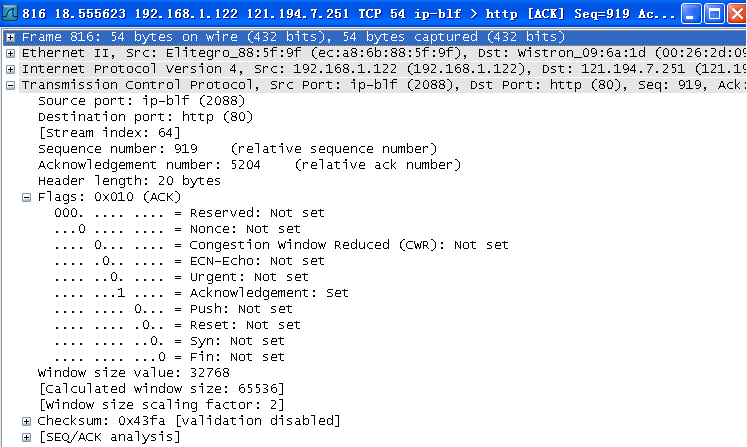
第二次挥手。序号:seq=919、确认号:ack=5204、FIN=0、ACK=1
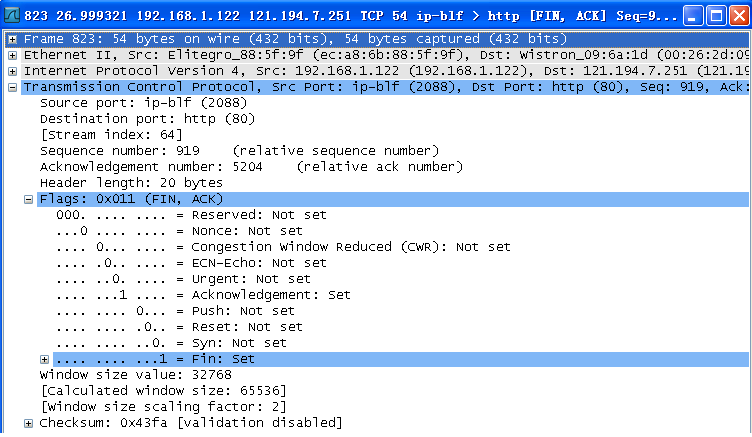
第三次挥手。序号:seq=919、确认号:ack=5204、ACK=1、FIN=1
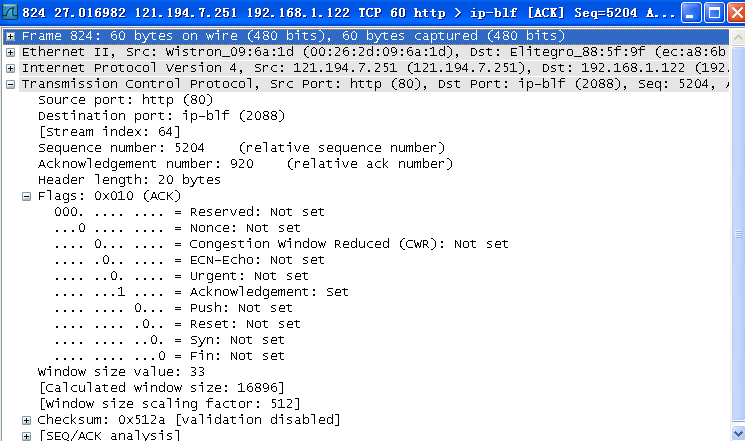
第四次挥手。序号:seq=5204、确认号:ack=920、FIN=0、ACK=1
(7)1. 释放请求由服务器端(121.194.7.251)发起的。
2. FIN报文段不携带数据,消耗一个序号。根据TCP规定,FIN报文段即使不携带数据,也消耗 掉一个序号。根据第二次挥手报文,确认号为5204,说明没有携带数据。
3. FIN报文段的序号是5203。
4. 由下图可以看出此报文前的一个报文的确认号为:ack=5203,确认号是期望对方下一个报文段的第一个数据字节的序号。即它等于前面已经传送过的数据的最后一个字节的序号加1。

(8)报文段的往返时间RTT(Round-Trip Time)
新的RTTs =(1-a)*(旧的RTTs)+ a*(新的RTT样本值)
新的RTTD = (1-b)*(旧的RTTD) + b*|RTTs – 新的RTT样本|
超时重传时间RTO = RTTs + 4 * RTTD;
以“tcp.srcport==1715”显示过滤规则过滤对应一个tcp端口的tcp连接。
然后保存为纯文本格式,并拷到Linux虚拟机中(为了使用perl环境):

perl脚本如下:
- #!/usr/bin/perl
- $i=0;
- @RTT;
- while(<>){
- if(/RTT/){
- @words = split(/ +/,$_);
- $RTT[$i++]=$words[8];
- }
- }
- $i=0;
- $RTTs=0;
- $a=0.125;
- $b=0.25;
- while($RTT[$i]){
- $RTTs *= (1-$a);
- $RTTs += $a*$RTT[$i];
- if($i==0){
- $RTTd=$RTT[$i]/2;
- }else{
- $RTTd *= (1-$b);
- $RTTd += $b * abs($RTTs-$RTT[$i]);
- }
- $RTO = $RTTs + 4*$RTTd;
- print "RTTs=",$RTTs,"\t";
- print "RTTd=",$RTTd,"\t";
- print "RTO=",$RTO,"\n";
- $i++;
- }
在终端执行:perl 3.plx tcplink
执行结果如下:

(9)以下是HTTP请求分组:
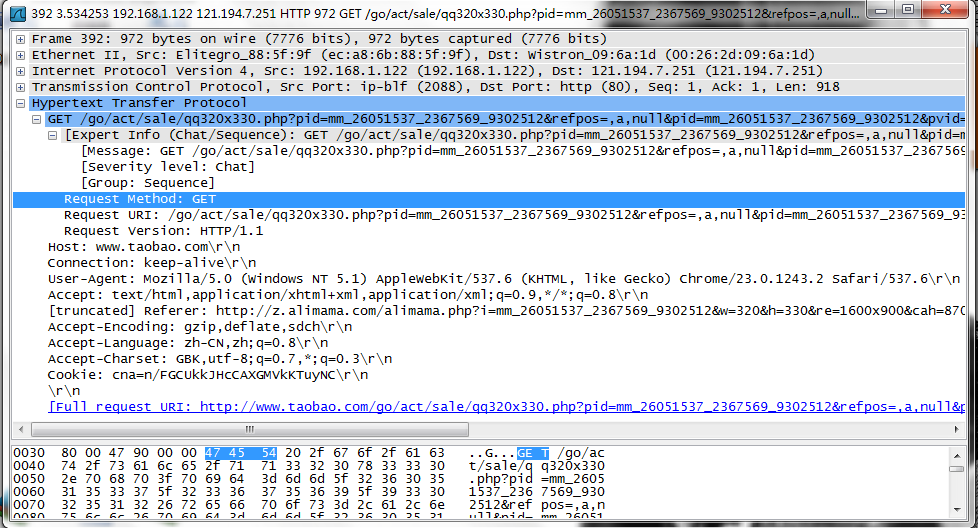
请求行:
Request Method:GET(请求的方法)
Request URL:/go/act/sale/qq320x330.php?pid=mm_26051537……(URL)
Request Version:HTTP/1.1(http版本)
首部行:
Host:www.taobao.com\r\n(主机的域名)
Connection:keep-alive\r\n(告诉服务器发送完请求文档后哦不释放链接)
User-Agent:Mozilla/5.0(windows NT 5.1) AppleWebkit/537.6(KHTML,like Gecko) chrome/23.0.1243.2 Safari/537.6(用户代理使用的基于Mozilla内核的浏览器)
Accept:text/html(希望接受的文档格式)
以下是HTTP响应分组:

开始行:
Request version:HTTP/1.1(版本)
Status code:200(状态码,2xx表示成功)
Reponse Phrase:OK
首部行:
Server:Tengine(web服务器是Tengine)
Date:Thu,06 Dec 2012 02:57:57 GMT
Connection:keep-alive
Vary:Accept-Encoding
(11)HTTP/1.1协议的持续连接有两种工作方式,即非流水线方式(without pipelining)和流水线方式(with pipelining)
非流水线方式的特点,是客户端在收到前一个响应后才能发出下一个请求。
流水线方式的特点,是客户端在收到HTTP的响应报文之前就能够接着发送新的值来请求报文。于是一个接一个的请求报文到达服务器后,服务器就可连续发回响应报文。流水线工作方式使TCP连接中的空闲时间减少。
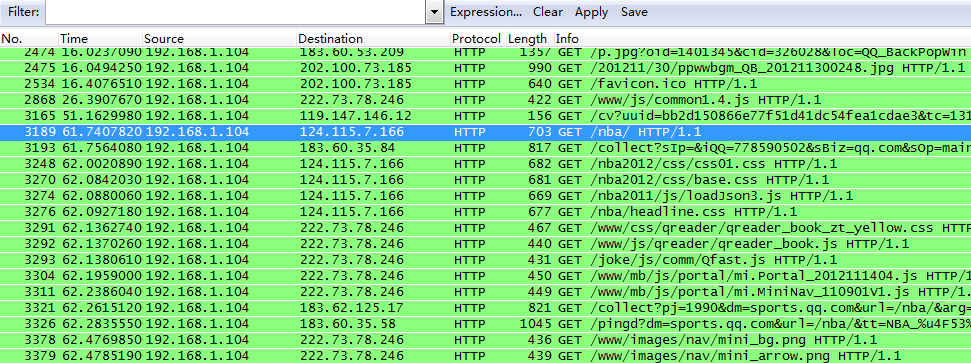
由上图可知,访问同一网站的不同页面采用了流水线方式。
如发现错误,欢迎给予指正。
本文出自 “开心菠菜” 博客,请务必保留此出处http://kaixinbocai.blog.51cto.com/3913323/1086745
posted on 2014-05-26 15:02
回忆之城 阅读(1407)
评论(0) 编辑 收藏 引用 所属分类:
测试技术相关