由于公司架构调整和业务方向的转变,我所在的项目组即将接手一个机器学习和数据挖掘的项目,为了后续更好地开展工作,也为了能提高自己的专业技能,我决定开始学习机器和数据挖掘方面的知识。

那么,问题就来了:到底应该从哪里开始学起呢?最开始我也买了一些机器学习相关的入门书籍,跟着听一些网络课程,但是我发现所有的课程都特别偏重理论,虽然机器学习、数据挖掘需要很强的理论基础才能做好,但是我个人更喜欢理论联系实际的学习方式,比如可以在了解某种基本原理的基础上,立刻用代码来实现它。
无意间从同事口中得知机器学习与数据挖掘的十大经典算法,我决定就从十大经典算法开始学习。
下面是我的学习路线:逐个掌握每种经典算法的算法思想、数学模型及Python代码实现,争取各个击破并融汇贯通。
好了,废话不多说了,我们先看第一种经典算法:PageRank算法。
一、PageRank算法的简介
PageRank算法即网页分级排名算法,它的提出者是谷歌的创始人之一拉里·佩奇(Larry Page),所以算法的名字就以Page命名。拉里·佩奇提出该算法时还是一名斯坦福大学的学生,(真是自古英雄出少年啊!)并且该算法曾在2001年9月获得美国国家专利。
PageRank算法是Google算法的重要内容之一,可以说它就是Google算法的降龙十八掌和倚天屠龙剑啊!
二、PageRank算法的核心思想
PageRank根据网站的外部链接和内部链接的数量和质量,衡量网站的价值。PageRank隐含的思想就是:每个到页面的链接都是对该页面的一次投票, 被链接的越多,就意味着被其他网站投票越多。一个网页所获得“投票”越多,说明这个网页越重要,它的被访问的概率越大,自然分级排名就越高,那么搜索结果它就越靠前。这就好比是一篇学术论文,论文被引用的次数越多,论文的影响因子越高,自然论文就越权威啦!
PageRank的核心思想归纳起来就两条:
1.如果一个网页被很多其他网页链接到的话说明这个网页比较重要,也就是PageRank值会相对较高。
2.如果一个PageRank值很高的网页链接到一个其他的网页,那么被链接到的网页的PageRank值会相应地因此而提高。
三、PageRank算法的数学模型
1、相关概念
出链:网页A中附加了网页B的链接,用户浏览A时可以通过点击该链接进入网页B,此时我们称A出链B。
入链:上面通过点击网页A中B-Link进入B,表示由A入链B。如果用户自己在浏览器输入栏输入网页B的URL,然后进入B,表示用户通过输入URL入链B。
无出链:如果一个网页A中没有附加任何的URL,则称A无出链。
只对自己出链:如果一个网页A中没有附加任何其他页面的URL,只有附加自己的URL,则称A只对自己出链。
PR值:就是指一个网站被访问的概率,PR值越高,被访问的概率越高,自然排名就高。
2、简单数学模型(不带a的数学模型)
首先,我们对网络上的所有网页做一个抽象,每个网页代表一个节点,如果从网页A中附加了网页B的链接,则表示从节点A指点节点B的有向边。那么整个WEB就被抽象成一张有向图。现在我们假设世界上只有四个网页,它们之间关系如下图:
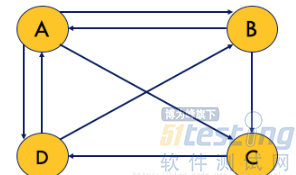
图 1
之前我们说过PageRank的思想就是,谁被引用的越多,谁的PR值越高。那么我们假设当用户停留在某个页面上时,他跳转到页面上任意一个链接的概率相同。
对任意一个网页我们用I(p)描述其重要性,称之为网页排序值(就是PR值)。假定网页Pj有Lj个链接,其中一个链接指向网页Pi,那么Pj将其重要性的1/Lj分给Pi,即Pi的网页重要性就是所有指向这个网页的其他网页所贡献的重要性之和。公式表示如下:
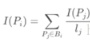
式中,Bi表示所有链接到Pi的网页集合。
为了方便数学分析,我们定义一个超链矩阵M[Mij]:
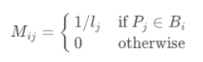
其中第i行j列的值Mij表示用户从页面j转到页面i的概率。
按照这个定义,图1的超链矩阵为

设初始时每个页面的rank值为1/N,这里就是1/4。按A—D顺序得到向量v:v=[1/4,1/4,1/4,1/4]
此时如果做矩阵乘法,使M*v就得到一个新的rank阵v’:M第一行分别是A、B、C和D转移到页面A的概率,而v的第一列分别是A、B、C和D当前的rank,因此用M的第一行乘以v的第一列,所得结果就是页面A最新rank的合理估计,故M*v的结果v’就分别代表A、B、C、D新rank值。
然后用M再乘以这个新的rank向量v’,又会产生一个rank向量。迭代这个过程,可以证明v最终会收敛,即v≈Mv,此时计算停止,最终得到的v’就是rankpage的排序结果:
V’=M*V----------(1)
3、复杂数学模型(带a的数学模型)
但是我们也注意到,要想上述迭代结果最终收敛,必须满足一个条件:图是强连通的,即从任意网页可以到达其他任意网页。假设我们把上面图中C到D的链接丢掉,C变成了一个终止点。再进行迭代,那么迭代的最终结果是v’=[0,0,0,0],显然算法失效了。除了终止点问题外,还有一个陷阱问题,即将图1中D到C的链接删除后,再加一条C指向C自身的链接。那么按上述迭代过程,最终v’=[0,0,1,0],此时算法也是失效的。
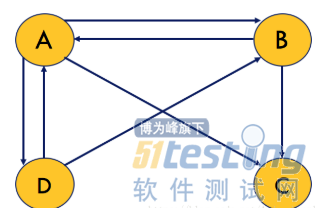
图2 终止点问题
 点击添加图片描述(最多60个字)
点击添加图片描述(最多60个字)图3 陷阱问题
为了解决终止点问题和陷阱问题,我们需要对算法进行改进:假设用户在选择下一个跳转的页面时,选择当前页及当前页上的链接的概率为a,选择其他页面的概率为(1-a),选择其他页面中每个页面的概率都相同为1/n,则计算PR值的公式演变为:
v′=αMv+(1?α)(1/n)-----(2)
四、PageRank算法的Python实现
下面我们以图3为例,分别用代码实现公式(1)和公式(2)的排序结果:
import numpy as np
M = [[0,1/2,0,1/2], [1/3,0,0,1/2], [1/3,1/2,1,0],[1/3,0,0,0]
U = [1/4,1/4,1/4,1/4]
U0 = np.array(U)
U_past_none_alpha = []
while True:
U = np.dot(M,U)
if str(U) == str(U_past_none_alpha):
Break
U_past_none_alpha = U
print('公式1的结果:',U)
U_past_has_alpha = []
while True:
U = 0.8*(np.dot(M,U))+0.2*U0
if str(U) == str(U_past_has_alpha):
Break
U_past_has_alpha = U
print('公式2的结果:',U)
输出结果如下:
C:\Users\1009\PycharmProjects\20190329\venv\Include\Include\Scripts\Python.exe C:/Users/1009/PycharmProjects/20190329/pagerank.py
公式1的结果:[0. 0. 1. 0.]
公式2的结果:[0.13172043 0.11917563 0.6639785 0.08512545]
Process finished with exit code 0
显然,公式(2)的结果更加科学准确!
五、后记:
PageRank算法就介绍到这里了,我的感觉就是按公式编码实现其实并不难,难的在于公式背后的数学逻辑思维。通过和做算法开发的同事交流,我才知道原来算法最最重要的就是思维,没有思维的算法就如同没有灵魂的躯体一样,完全不能适应复杂的现实场景的需求。谨以此文为开端,开始我的算法之旅,希望与广大测试同行一起进步!
加官方微信:sy51testing 回复关键词“学习”领取限量软件测试学习资料哦~~