链接
http://hr.tencent.com/pages/position/morelist.shtml?location=sz&sort=tec
主要JS:
http://hr.tencent.com/scripts/hr.js
http://hr.tencent.com/scripts/xmlparser.js
页面场景:
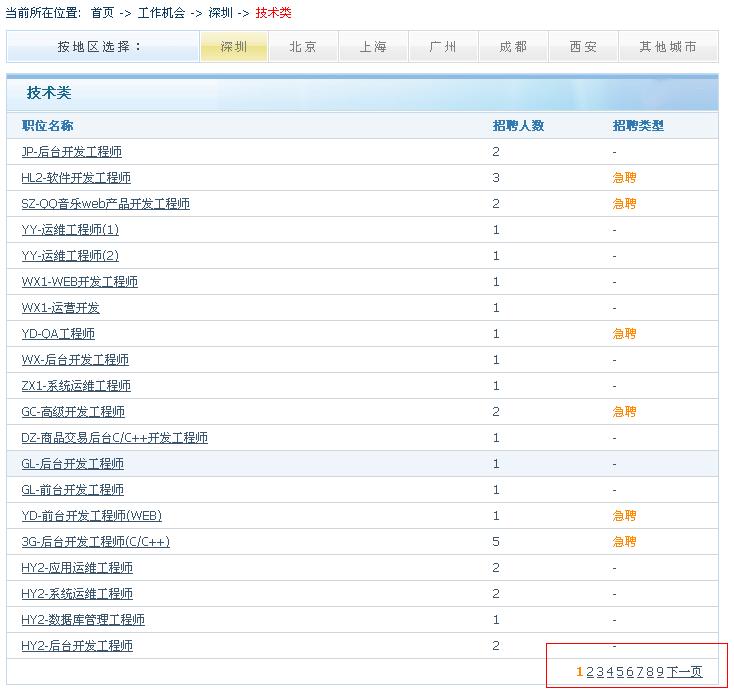
其中右下角的分页是无须刷新页面的,怎么实现的呢?
分析代码:
1、初始化启动
先看页面的源代码,只有一句js。
$(function(){
HRWriter.renderjoblist.render($("#listcontainer"));
});
Jquery式的代码,下一步看看HRWriter.renderjoblist.render有什么东东?打开“hr.js”。
2、HRWriter先找到HRWriter这个Function,900多行!,原来不只是renderjoblist,还有renderhotlist、renderlive等等。
这些renderxxx虽然内容不同,但都有类似的结构,他们都拥有render、rendercontent两个方法。
render是根据当前URL的链接字符串获取查询条件,然后使用Ajax请求服务器获取数据,最后调用rendercontent把从Ajax获取的XML数据转化为html,呈现于页面的某个容器标记。
3、renderjoblist重点看看HRWriter.renderjoblist。
先看看render方法,接受一个参数,这个就是要呈现数据的html一个容器,传入的是$("#listcontainer")。
//初始化呈现列表
render:function(container)
{
//获取查询字符串的值
var sort = querystring("sort");
var location = querystring("location");
//设置Banner高亮度
setnav("#nav"+location);
//设置“当前所在位置”的显示内容与样式
setlocation(location,false);
//设置“当前所在位置”当前分类链接
setsort(location, sort, true);
//初始化请求Ajax的链接
//解析出的URL类似“/data/sz_tec_list.xml?time=1206545022953”
var xmlurl = "/data/"+location+"_"+sort+"_list.xml?time="+(new Date().getTime());
$.ajax({dataType:"xml",type:"get",url:xmlurl,success:function(xmlDoc){
//分析XML,把结果存于HRWriter.renderjoblist.positions
//其中HRWriter.renderjoblist.positions.type为类型
// HRWriter.renderjoblist.positions.list为工作列表
HRWriter.renderjoblist.positions.type = XmlParser.GetNodeValue(xmlDoc.selectSingleNode("//type"));
var items = xmlDoc.selectNodes("//position");
HRWriter.renderjoblist.positions.list = new Array();
for(var i=0;i<items.length;i++)
{
var position = new Object();
position.id = XmlParser.GetNodeValue(items[i].selectSingleNode("id"));
position.positionname = XmlParser.GetNodeValue(items[i].selectSingleNode("positionname"));
position.avaiablenum = XmlParser.GetNodeValue(items[i].selectSingleNode("avaiablenum"));
position.emergency = XmlParser.GetNodeValue(items[i].selectSingleNode("emergency"));
HRWriter.renderjoblist.positions.list.push(position);
}
//显示与html中
//rendercontent把数据转化为html
container.html(HRWriter.renderjoblist.rendercontent(HRWriter.renderjoblist.positions));
}});
},
我整理代码格式和添加了一些注释。
继续往下看到querystring方法。这是根据url获取查询字符串数据的方法。
function querystring(fieldName)
{
var urlString = document.location.search;
if(urlString)
{
var typeQu = fieldName+"=";
var urlEnd = urlString.indexOf(typeQu);
if(urlEnd != -1)
{
var paramsUrl = urlString.substring(urlEnd+typeQu.length);
var isEnd = paramsUrl.indexOf('&');
if(isEnd != -1)
{
return paramsUrl.substring(0, isEnd);
}
else
{
return paramsUrl;
}
}
else
return null;
}
else
return null;
}
其中的算法很简单,先取得urlString(如?location=sz&sort=tec);
算计出(fieldName+'=')在查询字符串的索引,然后截取,(如sz&sort=tec);
在算计第一个&,做最后的截取。(如获取sz)。
回到renderjoblist.render,开始获取location和sort(地区和分类),即查询条件。然后用了3个setxxx的方法,作用是把导航栏部分,根据查询条件高亮度。

由左至右、上至下方向,分别起作用的函数为
setlocation(location,false);
setsort(location, sort, true);
setnav("#nav"+location);
4、Ajax
重点的Ajax请求,先利用查询条件,组合出需要请求的链接。
//初始化请求Ajax的链接
//解析出的URL类似“/data/sz_tec_list.xml?time=1206545022953”
var xmlurl = "/data/"+location+"_"+sort+"_list.xml?time="+(new Date().getTime());
我们直接用浏览器来看看这个链接(
http://hr.tencent.com/data/sz_tec_list.xml?time=1206545022953)返回的是什么东东?

原来用Ajax请求的xml数据是这些。主要的是positionlist,这些就是所有数据的集合。但需要注意的是,这里不止是“第一页”的数据,而是全部的数据。
$.ajax({dataType:"xml",type:"get",url:xmlurl,success:function(xmlDoc){
//分析XML,把结果存于HRWriter.renderjoblist.positions
//其中HRWriter.renderjoblist.positions.type为类型
// HRWriter.renderjoblist.positions.list为工作列表
HRWriter.renderjoblist.positions.type = XmlParser.GetNodeValue(xmlDoc.selectSingleNode("//type"));
var items = xmlDoc.selectNodes("//position");
HRWriter.renderjoblist.positions.list = new Array();
for(var i=0;i<items.length;i++)
{
var position = new Object();
position.id = XmlParser.GetNodeValue(items[i].selectSingleNode("id"));
position.positionname = XmlParser.GetNodeValue(items[i].selectSingleNode("positionname"));
position.avaiablenum = XmlParser.GetNodeValue(items[i].selectSingleNode("avaiablenum"));
position.emergency = XmlParser.GetNodeValue(items[i].selectSingleNode("emergency"));
HRWriter.renderjoblist.positions.list.push(position);
}
//显示与html中
//rendercontent把数据转化为html
container.html(HRWriter.renderjoblist.rendercontent(HRWriter.renderjoblist.positions));
}});
看看在最后请求成功后,success添加了一个回调函数,参数正是由Jquery解释XML的一个XMLDocument对象。
在Callback函数中,使用XmlParser获取节点的值(因为IE和FF获取xml的innerText值方式不同)。
解释XML数据把其存储在HRWriter.renderjoblist.positions,其中的list属性,是一个Array,存储xml各个position的内容。
最后使用HRWriter.renderjoblist.rendercontent把数据转换html呈现于container的html中。
5、rendercontent
rendercontent:function(positions)
{
var content = "";
var pageSize = HRWriter.renderjoblist.pageSize;
content += "<div class=\"jobdetailtitle\">";
content +="<h5>"+positions.type+"</h5>";
content +="</div>";
content +="<table class=\"joblist\">";
content +="<thead>";
content +="<tr>";
content +="<th>职位名称</th>";
content +="<th>招聘人数</th>";
content +="<th>招聘类型</th>";
content +="</tr>";
content +="</thead>";
content +="<tbody id=\"joblist\">";
content += HRWriter.renderjoblist.renderjoblist(0);
content +="</tbody>";
content +="<tfoot>";
content +="<tr>";
content +="<td colspan=\"3\">";
var pagecount = Math.ceil(positions.list.length/pageSize);
//初始化“上一页”为隐藏
content +="<a href=\"javascript:void(0)\" id=\"prepage\" style=\"display:none\" >上一页</a>";
//初始化“第一页”为当前页
content +="<a href=\"javascript:void(0)\" class=\"curpage\" onclick=\"HRWriter.renderjoblist.pagechanged(0);\" id=\"pageindex0\">1</a>";
for(var k = 1; k < pagecount; k++)
{
content +="<a href=\"javascript:void(0)\" onclick=\"HRWriter.renderjoblist.pagechanged("+k+");\" id=\"pageindex"+k+"\">"+(k+1)+"</a>";
}
//如果页数大于一页,则有“下一页”
if(pagecount>1)//next page
{
content +="<a href=\"javascript:void(0)\" id=\"nextpage\" onclick=\"HRWriter.renderjoblist.pagechanged(1);\" >下一页</a>";
}
content += "</td>";
content += "</tr>";
content += "</tfoot>";
content += "</table>";
return content;
},
这里就把初始化“第一页”的数据转化成html。
至此,才完成了初始化的任务,还有分页呢?这里注意的是在tfoot中,对每一个页数添加onclick事件的函数 -- HRWriter.renderjoblist.pagechanged。
6、pagechanged
pagechanged:function(pageindex)
{
//获取id为joblist的table
var joblist = $('#joblist');
//获取页数需要的数据
joblist.html(HRWriter.renderjoblist.renderjoblist(pageindex));
//取消旧的当前页数的样式
$("a.curpage").removeClass("curpage");
//为当前页数添加样式
$("#pageindex"+pageindex).addClass("curpage");
//计算页数
var pagecount = Math.ceil(HRWriter.renderjoblist.positions.list.length/HRWriter.renderjoblist.pageSize);
if(pageindex < pagecount-1)
{
$("#nextpage").attr("onclick", "");
$("#nextpage").unbind("click");
document.getElementById("nextpage").onclick = function(){HRWriter.renderjoblist.pagechanged(pageindex+1)};
//$("#nextpage").click(function(){alert('sd');HRWriter.renderjoblist.pagechanged(pageindex+1)});
$("#nextpage").css("display","");
}
//如果当前页数为最后一页,隐藏“下一页”
else
{
$("#nextpage").css("display","none");
}
if(pageindex>0)
{
$("#prepage").attr("onclick", "");
$("#prepage").unbind("click");
document.getElementById("prepage").onclick = function(){HRWriter.renderjoblist.pagechanged(pageindex-1)};
//$("#prepage").click(function(){HRWriter.renderjoblist.pagechanged(pageindex-1)});
$("#prepage").css("display","");
}
//如果当前页数为第一页,隐藏“上一页”
else
{
$("#prepage").css("display","none");
}
}
先忽略joblist.html(HRWriter.renderjoblist.renderjoblist(pageindex));
我们可以看到这个函数,没有获取数据的地方,主要是重组分页器的样式。
留意一下,刷新prepage(或nextpage)的click事件的方式。
为什么直接用unbind就不行了,一定要用document.getElementById("prepage").onclick = function(){...}
原来在rendercontent中,是在html为prepage的onclick赋值的,如<a id='prepage' onclick='xxxxx'>上一页</a>
正因为如此,jquery不能unbind在html写死的onclick函数,因此必须用document.getElementById("prepage").onclick = function(){...}方式重写。
至于,个人觉得
$("#prepage").attr("onclick", "");
$("#prepage").unbind("click");
document.getElementById("prepage").onclick = function(){HRWriter.renderjoblist.pagechanged(pageindex-1)};
3句有点多余,只有最后一句就可以了,或者要2、3就可以了。
7、renderjoblist
这是分页获取数据的方法。
renderjoblist:function(pageindex)
{
var pageSize = HRWriter.renderjoblist.pageSize;
var startPos = pageindex*pageSize;
var tempContent = "";
//获取URL中的location信息
var location = querystring("location");
//搜索内存中已有的数据HRWriter.renderjoblist.positions.list
//从中获取当前页数需要的数据
for(var j = startPos ; j < HRWriter.renderjoblist.positions.list.length && j<startPos+pageSize; j ++)
{
with(HRWriter.renderjoblist.positions.list[j])
{
//组合table中每行的数据
tempContent +="<tr onmouseover=\"this.className='mouseover'\" onmouseout=\"this.className=''\">";
tempContent +="<td class=\"title\">";
tempContent +="<a href=\"detail.shtml?jobid="+id+ "&location=" + location +"\">"+positionname+"</a>";
tempContent +="</td>";
tempContent +="<td class=\"availnum\">"+avaiablenum+"</td>";
if(emergency.indexOf("急") > -1)
tempContent +="<td class=\"type\"><span class=\"urgency\">急聘</span></td>";
else
tempContent +="<td class=\"type\"><span>-</span></td>";
tempContent +="</tr>";
}
}
return tempContent;
},
可以看到这里并没有地方用Ajax,因为在初始化第一次的时候,已经用Ajax把数据全部输出出来了,缓存于HRWriter.renderjoblist.positions.list变量中。
这里的工作只是遍历HRWriter.renderjoblist.positions.list,获取相应的数据组成html刷新container的html,就完成的分页的效果。
8、完整代码如下
renderjoblist:
{
positions:new Object(),
pageSize:20,
//初始化呈现列表
render:function(container)
{
//获取查询字符串的值
var sort = querystring("sort");
var location = querystring("location");
//设置Banner高亮度
setnav("#nav"+location);
//设置“当前所在位置”的显示内容与样式
setlocation(location,false);
//设置“当前所在位置”当前分类链接
setsort(location, sort, true);
//初始化请求Ajax的链接
//解析出的URL类似“/data/sz_tec_list.xml?time=1206545022953”
var xmlurl = "/data/"+location+"_"+sort+"_list.xml?time="+(new Date().getTime());
$.ajax({dataType:"xml",type:"get",url:xmlurl,success:function(xmlDoc){
//分析XML,把结果存于HRWriter.renderjoblist.positions
//其中HRWriter.renderjoblist.positions.type为类型
// HRWriter.renderjoblist.positions.list为工作列表
HRWriter.renderjoblist.positions.type = XmlParser.GetNodeValue(xmlDoc.selectSingleNode("//type"));
var items = xmlDoc.selectNodes("//position");
HRWriter.renderjoblist.positions.list = new Array();
for(var i=0;i<items.length;i++)
{
var position = new Object();
position.id = XmlParser.GetNodeValue(items[i].selectSingleNode("id"));
position.positionname = XmlParser.GetNodeValue(items[i].selectSingleNode("positionname"));
position.avaiablenum = XmlParser.GetNodeValue(items[i].selectSingleNode("avaiablenum"));
position.emergency = XmlParser.GetNodeValue(items[i].selectSingleNode("emergency"));
HRWriter.renderjoblist.positions.list.push(position);
}
//显示与html中
//rendercontent把数据转化为html
container.html(HRWriter.renderjoblist.rendercontent(HRWriter.renderjoblist.positions));
}});
},
rendercontent:function(positions)
{
var content = "";
var pageSize = HRWriter.renderjoblist.pageSize;
content += "<div class=\"jobdetailtitle\">";
content +="<h5>"+positions.type+"</h5>";
content +="</div>";
content +="<table class=\"joblist\">";
content +="<thead>";
content +="<tr>";
content +="<th>职位名称</th>";
content +="<th>招聘人数</th>";
content +="<th>招聘类型</th>";
content +="</tr>";
content +="</thead>";
content +="<tbody id=\"joblist\">";
content += HRWriter.renderjoblist.renderjoblist(0);
content +="</tbody>";
content +="<tfoot>";
content +="<tr>";
content +="<td colspan=\"3\">";
var pagecount = Math.ceil(positions.list.length/pageSize);
//初始化“上一页”为隐藏
content +="<a href=\"javascript:void(0)\" id=\"prepage\" style=\"display:none\" >上一页</a>";
//初始化“第一页”为当前页
content +="<a href=\"javascript:void(0)\" class=\"curpage\" onclick=\"HRWriter.renderjoblist.pagechanged(0);\" id=\"pageindex0\">1</a>";
for(var k = 1; k < pagecount; k++)
{
content +="<a href=\"javascript:void(0)\" onclick=\"HRWriter.renderjoblist.pagechanged("+k+");\" id=\"pageindex"+k+"\">"+(k+1)+"</a>";
}
//如果页数大于一页,则有“下一页”
if(pagecount>1)//next page
{
content +="<a href=\"javascript:void(0)\" id=\"nextpage\" onclick=\"HRWriter.renderjoblist.pagechanged(1);\" >下一页</a>";
}
content += "</td>";
content += "</tr>";
content += "</tfoot>";
content += "</table>";
return content;
},
renderjoblist:function(pageindex)
{
var pageSize = HRWriter.renderjoblist.pageSize;
var startPos = pageindex*pageSize;
var tempContent = "";
//获取URL中的location信息
var location = querystring("location");
//搜索内存中已有的数据HRWriter.renderjoblist.positions.list
//从中获取当前页数需要的数据
for(var j = startPos ; j < HRWriter.renderjoblist.positions.list.length && j<startPos+pageSize; j ++)
{
with(HRWriter.renderjoblist.positions.list[j])
{
//组合table中每行的数据
tempContent +="<tr onmouseover=\"this.className='mouseover'\" onmouseout=\"this.className=''\">";
tempContent +="<td class=\"title\">";
tempContent +="<a href=\"detail.shtml?jobid="+id+ "&location=" + location +"\">"+positionname+"</a>";
tempContent +="</td>";
tempContent +="<td class=\"availnum\">"+avaiablenum+"</td>";
if(emergency.indexOf("急") > -1)
tempContent +="<td class=\"type\"><span class=\"urgency\">急聘</span></td>";
else
tempContent +="<td class=\"type\"><span>-</span></td>";
tempContent +="</tr>";
}
}
return tempContent;
},
pagechanged:function(pageindex)
{
//获取id为joblist的table
var joblist = $('#joblist');
//获取页数需要的数据
joblist.html(HRWriter.renderjoblist.renderjoblist(pageindex));
//取消旧的当前页数的样式
$("a.curpage").removeClass("curpage");
//为当前页数添加样式
$("#pageindex"+pageindex).addClass("curpage");
//计算页数
var pagecount = Math.ceil(HRWriter.renderjoblist.positions.list.length/HRWriter.renderjoblist.pageSize);
if(pageindex < pagecount-1)
{
$("#nextpage").attr("onclick", "");
$("#nextpage").unbind("click");
document.getElementById("nextpage").onclick = function(){HRWriter.renderjoblist.pagechanged(pageindex+1)};
//$("#nextpage").click(function(){alert('sd');HRWriter.renderjoblist.pagechanged(pageindex+1)});
$("#nextpage").css("display","");
}
//如果当前页数为最后一页,隐藏“下一页”
else
{
$("#nextpage").css("display","none");
}
if(pageindex>0)
{
$("#prepage").attr("onclick", "");
$("#prepage").unbind("click");
document.getElementById("prepage").onclick = function(){HRWriter.renderjoblist.pagechanged(pageindex-1)};
//$("#prepage").click(function(){HRWriter.renderjoblist.pagechanged(pageindex-1)});
$("#prepage").css("display","");
}
//如果当前页数为第一页,隐藏“上一页”
else
{
$("#prepage").css("display","none");
}
}
},
9、总结
这段脚本不复杂,特点是一次性获取数据到js的变量,然后分页时在变量中遍历需要的数据。
缺点显而易见,如果数据量太大的时候,第一次加载时间会很长;而且翻页的时候,对客户端配置剩余内存低的,显示会滞慢。
本人认为,可以改善地方:
1、在组织html,添加字符串时,不要使用“+=”,尝试使用数组Array把字符串push进去,最后用join把字符串连接起来,效率会高点。
2、Ajax返回的直接是json的话,可以减少解析XML的时间。
3、尽量不要使用html嵌入js的方式,为元素绑定click方法,尽量在js代码做。