
(一) 概述
android的binder机制提供一种进程间通信的方法,使一个进程可以以类似远程过程调用的形式调用另一个进程所提供的功能。binder机制在Java环境和C/C++环境都有提供。
android的代码中,与C/C++的binder包括一些类型和接口的定义和实现,相关的代码在下面这几个文件中:
frameworks\base\include\utils\IInterface.h
frameworks\base\include\utils\Binder.h
frameworks\base\include\utils\BpBinder.h
frameworks\base\include\utils\IBinder
frameworks\base\include\utils\Parcel.h
frameworks\base\include\utils\IPCThreadState.h
frameworks\base\include\utils\ProcessState.h
frameworks\base\libs\utils\Binder.cpp
frameworks\base\libs\utils\BpBinder.cpp
frameworks\base\libs\utils\IInterface.cpp
frameworks\base\libs\utils\IPCThreadState.cpp
frameworks\base\libs\utils\Parcel.cpp
frameworks\base\libs\utils\ProcessState.cpp
为了了解这些类、接口之间的关系以及binder的实现机制,最好是结合一个例子来进行研究。我选择的例子是android自带的媒体播放器的实现。其媒体播放器的相关代码在下面这些目录中:
frameworks\base\include\media
frameworks\base\media
使用startUML的反向工程功能分析上面这些代码,并进行了一定的整理之后,得到下面这幅类图(点击可查看原尺寸图片)。

android的媒体播放功能分成两部分,一部分是媒体播放应用,一部分是媒体播放服务(MediaServer,在系统启动时由init所启动,具可参 考init.rc文件)。这两部分分别跑在不同的进程中。媒体播放应用包括Java程序和部分C++代码,媒体播放服务是C++代码,并且需要调用外部模 块opencore来实现真正的媒体播放。媒体播放应用和媒体播放服务之间需要通过binder机制来进行相互调用,这些调用包括:
(1)媒体播放应用向媒体播放服务发控制指令
(2)媒体播放服务向媒体播放应用发事件通知(notify)
媒体播放服务对外提供多个接口,在上面得图中包括其中的2个接口:IMediaService和IMediaPlayer,IMediaplayer用于 创建和管理播放实例,而IMediaplayer接口则是播放接口,用于实现指定媒体文件的播放以及播放过程的控制。
上面的图中还有媒体播放应用向媒体播放服务提供的1个接口:IMediaPlayerClient,用于接收notify。
这些接口因为需要跨进程调用,因此需要用到binder机制。每个接口包括两部分实现,一部分是接口功能的真正实现(BnInterface),这部分运 行在接口提供进程中;另一部分是接口的proxy(BpInterface),这部分运行在调用接口的进程中。binder的作用就是让这两部分之间建立 联系。下图是整个播放器的一个概要说明。

媒体播放器比较复杂一些,总共实现了3个接口,不过要了解binder的机制,只需要研究其中一个接口就足够了。在这里选择IMediaPlayerService接口来看一下。
IMediaPlayerService接口包括六个功能函数:create(url)、create(fd)、decode(url)、 decode(fd)、createMediaRecord()、createMetadataRetriever()。在这里不介绍这些函数是做什么 的,我们只关注如何通过binder还提供这些函数接口。
(二) 接口定义
(1) 定义接口类
首先定义IMediaPlayerService类,这是一个接口类(C++的术语应该叫纯虚类)。该接口类定义在文件frameworks\base\include\media\IMediaPlayerService.h。代码如下:
| class IMediaPlayerService: public IInterface
{
public:
DECLARE_META_INTERFACE(MediaPlayerService);
virtual sp<IMediaRecorder> createMediaRecorder(pid_t pid) = 0;
virtual sp<IMediaMetadataRetriever> createMetadataRetriever(pid_t pid) = 0;
virtual sp<IMediaPlayer> create(pid_t pid, const sp<IMediaPlayerClient>& client, const char* url) = 0;
virtual sp<IMediaPlayer> create(pid_t pid, const sp<IMediaPlayerClient>& client, int fd, int64_t offset, int64_t length) = 0;
virtual sp<IMemory> decode(const char* url, uint32_t *pSampleRate, int* pNumChannels, int* pFormat) = 0;
virtual sp<IMemory> decode(int fd, int64_t offset, int64_t length, uint32_t *pSampleRate, int* pNumChannels, int* pFormat) = 0;
};
|
|
可以看到,在这个接口类中定义了IMediaPlayerService需要提供的6个函数接口,因为是接口类,所以定义为纯虚函数。需要注意这个接口类的名称有严格要求,必须是以大写字母I开始。
重点关注在这些函数前面的一个宏定义: DECLARE_META_INTERFACE(MediaPlayerService)。这个宏定义必须要有,其中封装了实现binder所需要的一些 类成员变量和成员函数通过这些成员函数可以为一个binder实现创建proxy。这个宏定义在问价frameworks\base\include \utils\IInterface.h里,在后面还会讲到。这个宏定义的参数必须是接口类的名称去除字母I后剩下的部分。
另外说明一下,可以看到接口类中所定义的函数的返回值都是sp<xxxx>的形式,看起来有点怪异。sp是android中定义的一个模板 类,用于实现智能指针功能。sp<IMediaPlayer>就是IMediaPlayer的智能指针,可以简单地把它看成是标准C++中的 指针定义即 IMediaPlayer* 即可。
(2) 定义和实现binder类
binder类包括两个,一个是接口实现类,一个接口代理类。接口代理类继承自BpInterface,接口实现类继承自BnInterface。这两个基类都是模板类,封装了binder的进程间通信机制,这样使用者无需关注底层通信实现细节。
对于IMediaPlayerService接口,其binder接口实现类为BnMediaPlayerService,接口代理类为 BpMediaPlayerService。需注意这两个类的名称有严格要求,必须以Bn和Bp开头,并且后面的部分必须是前面所定义的接口类的名称去除 字母'I’。比如前面所定义的接口类为IMediaPlayerService,去除字母I后是MediaPlayerService,所以两个 binder类的名称分别是BnMediaPlayerService和BpMediaPlayerService。为什么有这样的要求?原因就在前面提 到的宏定义DECLARE_META_INTERFACE()和另一个宏定义IMPLEMENT_META_INTERFACE()里面。有兴趣的话可以 去看一下,这两个宏定义都在文件frameworks\base\include\utils\IInterface.h里。
BpMediaPlayerService是一个最终实现类。定义并且实现在在文件frameworks\base\media\libmidia \IMediaPlayerService.cpp中。在看BpMediaPlayerService的代码之前,先看一下在 IMediaPlayerService.cpp文件的开始部分的一个枚举定义:
enum {
CREATE_URL = IBinder::FIRST_CALL_TRANSACTION,
CREATE_FD,
DECODE_URL,
DECODE_FD,
CREATE_MEDIA_RECORDER,
CREATE_METADATA_RETRIEVER,
};
这些6个枚举定义对应于IMediaPlayerService接口所提供的6个功能函数,可以称为这些功能函数的功能代码,用于在进程之间进行RPC是 标识需要调用哪个函数。如果不想定义这些枚举值,在后面需要用到这些值的地方直接写上1,2,3,4,5,6也是可以的,不过……一个合适的程序员会这么 干吗?
下面看一下BpMediaPlayerService的代码。
(3) BpMediaPlayerService代码分析
class BpMediaPlayerService: public BpInterface<IMediaPlayerService>
{
public:
BpMediaPlayerService(const sp<IBinder>& impl)
: BpInterface<IMediaPlayerService>(impl)
{
}
virtual sp<IMediaMetadataRetriever> createMetadataRetriever(pid_t pid)
{
Parcel data, reply;
data.writeInterfaceToken(IMediaPlayerService::getInterfaceDescriptor());
data.writeInt32(pid);
remote()->transact(CREATE_METADATA_RETRIEVER, data, &reply);
return interface_cast<IMediaMetadataRetriever>(reply.readStrongBinder());
}
virtual sp<IMediaPlayer> create(pid_t pid, const sp<IMediaPlayerClient>& client, const char* url)
{
Parcel data, reply;
data.writeInterfaceToken(IMediaPlayerService::getInterfaceDescriptor());
data.writeInt32(pid);
data.writeStrongBinder(client->asBinder());
data.writeCString(url);
remote()->transact(CREATE_URL, data, &reply);
return interface_cast<IMediaPlayer>(reply.readStrongBinder());
}
virtual sp<IMediaRecorder> createMediaRecorder(pid_t pid)
{
Parcel data, reply;
data.writeInterfaceToken(IMediaPlayerService::getInterfaceDescriptor());
data.writeInt32(pid);
remote()->transact(CREATE_MEDIA_RECORDER, data, &reply);
return interface_cast<IMediaRecorder>(reply.readStrongBinder());
}
virtual sp<IMediaPlayer> create(pid_t pid, const sp<IMediaPlayerClient>& client, int fd, int64_t offset, int64_t length)
{
Parcel data, reply;
data.writeInterfaceToken(IMediaPlayerService::getInterfaceDescriptor());
data.writeInt32(pid);
data.writeStrongBinder(client->asBinder());
data.writeFileDescriptor(fd);
data.writeInt64(offset);
data.writeInt64(length);
remote()->transact(CREATE_FD, data, &reply);
return interface_cast<IMediaPlayer>(reply.readStrongBinder());
}
virtual sp<IMemory> decode(const char* url, uint32_t *pSampleRate, int* pNumChannels, int* pFormat)
{
Parcel data, reply;
data.writeInterfaceToken(IMediaPlayerService::getInterfaceDescriptor());
data.writeCString(url);
remote()->transact(DECODE_URL, data, &reply);
*pSampleRate = uint32_t(reply.readInt32());
*pNumChannels = reply.readInt32();
*pFormat = reply.readInt32();
return interface_cast<IMemory>(reply.readStrongBinder());
}
virtual sp<IMemory> decode(int fd, int64_t offset, int64_t length, uint32_t *pSampleRate, int* pNumChannels, int* pFormat)
{
Parcel data, reply;
data.writeInterfaceToken(IMediaPlayerService::getInterfaceDescriptor());
data.writeFileDescriptor(fd);
data.writeInt64(offset);
data.writeInt64(length);
remote()->transact(DECODE_FD, data, &reply);
*pSampleRate = uint32_t(reply.readInt32());
*pNumChannels = reply.readInt32();
*pFormat = reply.readInt32();
return interface_cast<IMemory>(reply.readStrongBinder());
}
};
首先可以看到,这个类继承自模板类BpInterface,指定类型为接口类IMediaPlayerService。BpInterface模板类定义 在文件IInterface.h。看一下BpInterface的定义就可以发现,BpMediaPlayerService这样定义了以后,事实上间接 继承了IMediaPlayerService,从而可以提供IMediaPlayerService接口所定义的接口函数。 BpMediaPlayerService需要实现这些接口函数。在一个简单的构造函数之后,就是这些接口函数的实现。可以看到,所有的接口函数的实现方 法都是一致的,都是通过binder所提供的机制将参数仍给binder的实现类,并获取返回值。这也就是这个类之所以成为代理类的原因。下面具体看一下 一个接口函数。这里选的是函数create(url)。
virtual sp<IMediaPlayer> create(pid_t pid, const sp<IMediaPlayerClient>& client, const char* url)
{
Parcel data, reply;
data.writeInterfaceToken(IMediaPlayerService::getInterfaceDescriptor());
data.writeInt32(pid);
data.writeStrongBinder(client->asBinder());
data.writeCString(url);
remote()->transact(CREATE_URL, data, &reply);
return interface_cast<IMediaPlayer>(reply.readStrongBinder());
}
这个接口函数的参数指定了一个URL,函数将为这个URL创建一个播放器实例用于播放该URL。
函数首先定义了两个局部变量data和reply,变量的类型都是Parcel。Parcel是一个专为binder通信的数据传送而定义的类,该类提供 了对多种类型的数据的封装功能,同时提供多个数据读取和写入函数,用于多种类型的数据的写入和读取,支持的数据类型既包括简单数据类型,也包括对象。这里 定义的变量data是用于封装create()函数调用所需要的输入参数,而reply则是用于封装调用的返回数据(包括输出参数的值和函数返回值)。
函数首先向data中写入各种数据。第一个写入的是接口的一个描述字符串,binder的实现类中会用这个字符串来对接口做验证,防止调用错误。这个字符 串也可以不写,如果不写,在binder实现类中相应的也就不要做验证了。跟在描述字符串后面写入的是该接口函数所需要的各种的输入参数。需要说明的 是,Pacel提供一种先入先出的数据存储方式,即数据的写入顺序和读取顺序必须严格一致,否则将会出错。
完成数据写入后,函数调用remote()->transact()用于完成binder通信。transact()函数的第一个参数就是前面提到 过的功能代码。transact()的功能是将data中的数据传给binder的实现类,函数调用结束后,reply中将包含返回数据。首先来看看 remote()成员函数。前面讲到过BpMediaPlayerService通过继承BpInterface模板类间接继承了 IMediaPlayerService接口类,其实BpInterface类是一个有两个父类的多重继承子类,另一个父类是 BpRefbase(frameworks\base\include\utils\Binder.h)。remote()就是继承自BpRefBase 类的一个成员函数,该函数返回BpRefBase类中定义的一个私有属性mRemote。mRemote是对IBinder接口类的子类BpBinder 的一个对象的引用(参考前面的类关系图)。transact()函数在IBinder接口类中定义(frameworks\base\include \utils\Binder.h),并在BpBinder类中实现(frameworks\base\include\utils \BpBinder.h、frameworks\base\libs\utils\BpBinder.cpp)。在transact()函数中将调用 IPCThreadState类的transact()函数,并进而通过Lniux内核中的android共享内存驱动来实现进程间通信。不过这些细节这 里就不多说了。在这里BpBinder类对象是一个关键,是实现Binder代理的核心之一。BpBinder类可以看成是一个通信handle(类似于 网络编程中的socket),用于实现进程间通信。接下来需要研究的是这个BpBinder类对象(即mRemote成员变量的值)是从哪里来的。
回过头来BpMediaPlayerService的构造函数(看前面的代码)。该构造函数的参数是一个IBinder对象的引用。mRemote的值就 是在这里传进来的这个对象。那么这个对象又是怎么来的呢?要搞清楚这一点就需要找到创建BpMediaPlayerService类的实例的代码,这个代 码就就跟在该类的定义代码的下面。继续看IMediaPlayerService.cpp文件,在BpMediaPlayerService类定义的后 面,是下面这样一行代码:
IMPLEMENT_META_INTERFACE(MediaPlayerService, "android.hardware.IMediaPlayerService");
这行代码调用了一个宏定义IMPLEMENT_META_INTERFACE()。这个宏定义与前面提到过的 DECLARE_META_INTERFACE()相呼应。看名字就知道,IMPLEMENT_META_INTERFACE()宏是对 DECLARE_META_INTERFACE()所定义的成员函数的具体实现。这个宏的第一个参数与DECLARE_META_INTERFACE() 的参数需完全一样,第二参数是接口的描述字符串(这个字符串前面也已经讲到过了)。描述字符串不重要,重要的是宏里面定义的一个静态成员函数 asInterface()。BpMediaPlayerService的类实例是在IMediaPlayerService的静态成员函数 asInterface()中创建的,在IInterface.h中定义了一个内联函数interface_cast(),对这个成员函数进行了封装。通 过看代码容易知道,BpMediaPlayerService的构造函数的参数是通过interface_cast()的参数传进来的。
好,下面就该看看这个interface_cast()是在哪里调用的,它的参数到底是什么。找到frameworks\base\media \libmedia\mediaplayer.cpp文件,其中的MediaPlayer::getMediaPlayerService()的实现代 码:
const sp<IMediaPlayerService>& MediaPlayer::getMediaPlayerService()
{
Mutex::Autolock _l(sServiceLock);
if (sMediaPlayerService.get() == 0) {
sp<IServiceManager> sm = defaultServiceManager();
sp<IBinder> binder;
do {
binder = sm->getService(String16("media.player"));
if (binder != 0)
break;
LOGW("MediaPlayerService not published, waiting...");
usleep(500000); // 0.5 s
} while(true);
if (sDeathNotifier == NULL) {
sDeathNotifier = new DeathNotifier();
}
binder->linkToDeath(sDeathNotifier);
sMediaPlayerService = interface_cast<IMediaPlayerService>(binder);
}
LOGE_IF(sMediaPlayerService==0, "no MediaPlayerService!?");
return sMediaPlayerService;
}
看一下上面这段代码中的红色字体部分。结合前面的分析,可知BpBinder类的对象实例是从android的服务管理器的getService()函数中获取,进一步追进去,会发现下面这样一段代码:
{
Parcel data, reply;
data.writeInterfaceToken(IServiceManager::getInterfaceDescriptor());
data.writeString16(name);
remote()->transact(CHECK_SERVICE_TRANSACTION, data, &reply);
return reply.readStrongBinder();
}
Android的服务管理器是一个单独的进程,也向外提供接口。这段代码的含义,是通过Android的服务管理器的接口代理,请求调用服务管理器的 checkService()接口函数,查找指定的服务(上面就是查找media.player服务),查找成功后返回一个BpBinder类的对象实 例,用于供IMediaPlayerService代理使用。这个对象BpBinder是在Parcel::readStrongBinder()函数里 面创建的。那么到底是怎么创建出来的呢?在这里没有必要追到ServiceManager的实现代码里去,毕竟我们只是想知道BpBinder的对象是如 何创建的,我们可以换一个例子来看。回到前面的BpMediaPlayerService::create()函数的实现,是不是很眼熟。没错,在那个函 数里也创建了一个BpBinder类对象,那个对象是是给IMediaPlayer接口代理使用的。虽然接口不同,但是创建原理是一样的。我们继续,下面 该到binder的另一个类——实现类的代码了。
(3) BnMediaPlayerService代码分析
BnMediaPlayerService类的定义在文件frameworks\base\include\media \IMediaPlayService.h,实现则与BpMediaPlayerService一样是在文件frameworks\base\media \libmidia\IMediaPlayerService.cpp中。类定义的代码如下:
class BnMediaPlayerService: public BnInterface<IMediaPlayerService>
{
public:
virtual status_t onTransact( uint32_t code,
const Parcel& data,
Parcel* reply,
uint32_t flags = 0);
};
这个类继承自BnInterface模板类,约束类型为IMediaPlayerService。看一下BnInterface模板类的定义 (IInterface.h)就可以知道,BnMediaPlayerService间接继承了IMediaPlayerService接口类。不过 BnInterface类并没有实现IMediaPlayerService所定义的6个接口函数,因此BnInterface还是一个纯虚类。这些接口 需要在BnMediaPlayerService的子类中真正实现,这个子类就是MediaPlayerService(frameworks\base \media\libmidiaservice\MediaPlayerService.h,frameworks\base\media \libmidiaservice\MediaPlayerService.cpp)。在BnMediaPlayerService的成员函数 onTransact()中,需要调用这6个接口函数。BnMediaPlayerService中主要就是定义并实现了onTransact()函数。 当在代理那边调用了transact()函数后,这边的onTransact()函数就会被调用。BnMediaPlayerService的实现代码如 下:
#define CHECK_INTERFACE(interface, data, reply) \
do { if (!data.enforceInterface(interface::getInterfaceDescriptor())) { \
LOGW("Call incorrectly routed to " #interface); \
return PERMISSION_DENIED; \
} } while (0)
status_t BnMediaPlayerService::onTransact(
uint32_t code, const Parcel& data, Parcel* reply, uint32_t flags)
{
switch(code) {
case CREATE_URL: {
CHECK_INTERFACE(IMediaPlayerService, data, reply);
pid_t pid = data.readInt32();
sp<IMediaPlayerClient> client = interface_cast<IMediaPlayerClient>(data.readStrongBinder());
const char* url = data.readCString();
sp<IMediaPlayer> player = create(pid, client, url);
reply->writeStrongBinder(player->asBinder());
return NO_ERROR;
} break;
case CREATE_FD: {
CHECK_INTERFACE(IMediaPlayerService, data, reply);
pid_t pid = data.readInt32();
sp<IMediaPlayerClient> client = interface_cast<IMediaPlayerClient>(data.readStrongBinder());
int fd = dup(data.readFileDescriptor());
int64_t offset = data.readInt64();
int64_t length = data.readInt64();
sp<IMediaPlayer> player = create(pid, client, fd, offset, length);
reply->writeStrongBinder(player->asBinder());
return NO_ERROR;
} break;
case DECODE_URL: {
CHECK_INTERFACE(IMediaPlayerService, data, reply);
const char* url = data.readCString();
uint32_t sampleRate;
int numChannels;
int format;
sp<IMemory> player = decode(url, &sampleRate, &numChannels, &format);
reply->writeInt32(sampleRate);
reply->writeInt32(numChannels);
reply->writeInt32(format);
reply->writeStrongBinder(player->asBinder());
return NO_ERROR;
} break;
case DECODE_FD: {
CHECK_INTERFACE(IMediaPlayerService, data, reply);
int fd = dup(data.readFileDescriptor());
int64_t offset = data.readInt64();
int64_t length = data.readInt64();
uint32_t sampleRate;
int numChannels;
int format;
sp<IMemory> player = decode(fd, offset, length, &sampleRate, &numChannels, &format);
reply->writeInt32(sampleRate);
reply->writeInt32(numChannels);
reply->writeInt32(format);
reply->writeStrongBinder(player->asBinder());
return NO_ERROR;
} break;
case CREATE_MEDIA_RECORDER: {
CHECK_INTERFACE(IMediaPlayerService, data, reply);
pid_t pid = data.readInt32();
sp<IMediaRecorder> recorder = createMediaRecorder(pid);
reply->writeStrongBinder(recorder->asBinder());
return NO_ERROR;
} break;
case CREATE_METADATA_RETRIEVER: {
CHECK_INTERFACE(IMediaPlayerService, data, reply);
pid_t pid = data.readInt32();
sp<IMediaMetadataRetriever> retriever = createMetadataRetriever(pid);
reply->writeStrongBinder(retriever->asBinder());
return NO_ERROR;
} break;
default:
return BBinder::onTransact(code, data, reply, flags);
}
}
首先是一个宏定义CHECK_INTERFACE(),这个宏定义的作用是检查接口的描述字符串,这个前面也提到过,不需细说。然后就是 onTrasact()函数的实现。这个函数的结构也很简单,就是根据参数code的值分别执行不同的功能调用。code的取值就是前面提到过的接口功能 代码。函数的参数除了code,还包括Parcel类的两个对象data和reply,分别用于传送输入参数和返回数据,与transact()函数的参 数相对应。还有一个参数flag在这里用不上,不讨论。对应我们前面所选择的接口函数的例子create(url),看看这边对应的实现:
case CREATE_URL: {
CHECK_INTERFACE(IMediaPlayerService, data, reply);
pid_t pid = data.readInt32();
sp<IMediaPlayerClient> client = interface_cast<IMediaPlayerClient>(data.readStrongBinder());
const char* url = data.readCString();
sp<IMediaPlayer> player = create(pid, client, url);
reply->writeStrongBinder(player->asBinder());
return NO_ERROR;
}
首先是从data对象中依次取出各项输入参数,然后调用接口函数create()(将在子类MediaPlayerService中实现),最后向reply中写入返回数据。这个函数返回后,代理那边的transact()也会跟着返回。
那么onTransact()函数是怎么被调用的呢?通过查看BnInterface模板类的定义可以看到,这个类也是一个多重继承类,另一个父类是 BBinder(frameworks\base\include\utils\Binder.h,frameworks\base\libs \utils\Binder.cpp)。BBinder类继承自IBinder,也实现了transact()函数,在这个函数中调用 onTransact()函数。而BBinder对象的transact()函数则是在IPCThreadState类的 executeCommand()成员函数中调用的。这已经涉及到较底层的实现,在这里不再多说。
上面这部分代码还与前面提到过的BpBinder对象的创建有关系。看其中的红色字体部分,通过create()函数调用会创建一个 IMediaPlayer接口类的子类的对象,这个对象其实是MediaPlayerService::Client类(可以看一下 MediaPlayerService的定义)的对象实例,而MediaPlayerService::Client类是继承自 BnMediaPlayer类的,与BnMediaPlayerService类类似,BnMediaPlayer其实也是一个binder实现类(是 BBinder的子类,进而也是IBinder的子类)。在上述代码中,通过Parcel的writeStrongBinder()函数将这个对象写入 reply,而在代理侧,通过Parcel的readStrongBinder()函数读取则可以得到一个BpBinder的对象。至于类的具体创建过程 已经封装在Parcel类的定义中,这里就不再多说了。
(4) 接口功能的真正实现
到这里两个binder类就已经定义完了,下面就是IMediaPlayerService接口函数的真正实现。前面已经说过这些函数在类 MediaPlayerService中实现。这个类继承自BnMediaPlayerService,也间接地继承了 IMediaPlayerService接口类定义的6个功能函数,只需要按照正常方式实现这6个功能函数即可,当然为了实现这6个函数就需要其它一大堆 的东西,不过这些具体的实现方法已经与binder机制无关,不再多说。
在MediaPlayerService类中定义了一个静态函数instantiate(),在这个函数中创建MediaPlayerService的对 象实例,并将这个对象注册到服务管理器中。这样需要使用的时候就可以从服务管理器获取IMediaPlayerService的代理对象。这个 instantiate()是在MediaServer程序的main()函数中调用的。
void MediaPlayerService::instantiate() {
defaultServiceManager()->addService(
String16("media.player"), new MediaPlayerService());
}
(三) 总结一下
说了这么多,总结一下。下图是binder机制的层次模型。

如果一个服务需要通过binder机制对外提供跨进程的接口,需要做下面这些事情。
(1) 第一步,需要为这个接口定义一个继承自IInterface的接口类,假设叫做IMyService。
(2) 第二步,需要定义两个binder类,其中一个是代理类BpMyService,需继承自BpInterface;另一个是实现类BnMyService,需继承自BnInterface。
(3) 第三步,定义BnMyService的子类,这个子类可以是任何名字,比如就叫MyService,在其中真正实现接口所提供的各个函数。
(4) 第四步,创建MyService的实例,注册到服务管理器(如IMediaPlayerService),也可以在其它接口的函数中创建(如上面的IMediaPlayer)。
posted @
2011-11-03 11:56 lfc 阅读(1512) |
评论 (0) |
编辑 收藏SurfaceFlinger在系统启动阶段作为系统服务被加载。应用程序中的每个窗口,对应本地代码中的Surface,而Surface又对应 于SurfaceFlinger中的各个Layer,SurfaceFlinger的主要作用是为这些Layer申请内存,根据应用程序的请求管理这些 Layer显示、隐藏、重画等操作,最终由SurfaceFlinger把所有的Layer组合到一起,显示到显示器上。当一个应用程序需要在一个 Surface上进行画图操作时,首先要拿到这个Surface在内存中的起始地址,而这块内存是在SurfaceFlinger中分配的,因为 SurfaceFlinger和应用程序并不是运行在同一个进程中,如何在应用客户端(Surface)和服务端(SurfaceFlinger - Layer)之间传递和同步显示缓冲区?这正是本文要讨论的内容。
Surface的创建过程
我们先看看Android如何创建一个Surface,下面的序列图展示了整个创建过程。
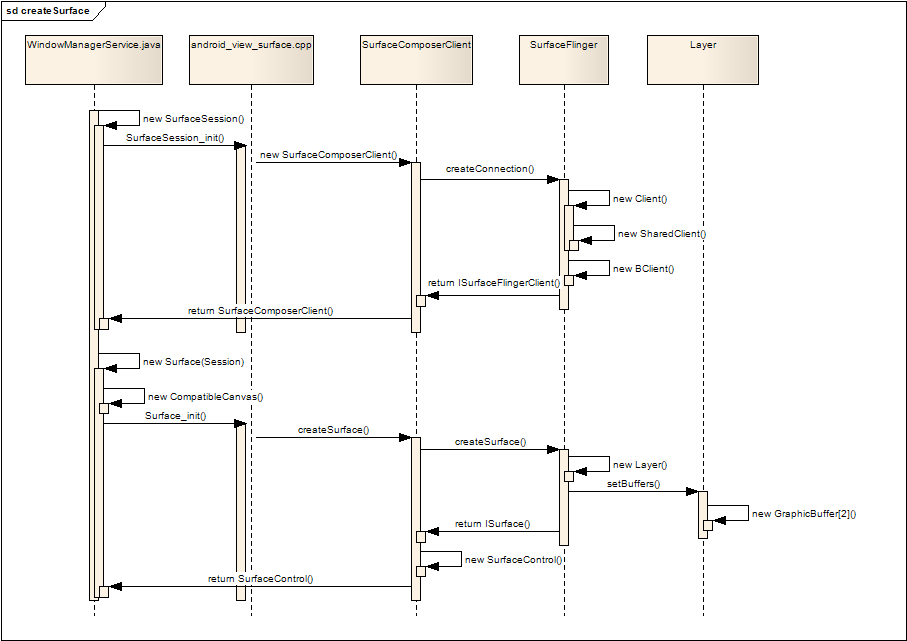
图一 Surface的创建过程
创建Surface的过程基本上分为两步:
1. 建立SurfaceSession
第一步通常只执行一次,目的是创建一个SurfaceComposerClient的实例,JAVA层通过JNI调用本地代码,本地代码创建一个 SurfaceComposerClient的实例,SurfaceComposerClient通过ISurfaceComposer接口调用 SurfaceFlinger的createConnection,SurfaceFlinger返回一个ISurfaceFlingerClient接 口给SurfaceComposerClient,在createConnection的过程中,SurfaceFlinger创建了用于管理缓冲区切换 的SharedClient,关于SharedClient我们下面再介绍,最后,本地层把SurfaceComposerClient的实例返回给 JAVA层,完成SurfaceSession的建立。
2. 利用SurfaceSession创建Surface
JAVA层通过JNI调用本地代码Surface_Init(),本地代码首先取得第一步创建的SurfaceComposerClient实例, 通过SurfaceComposerClient,调用ISurfaceFlingerClient接口的createSurface方法,进入 SurfaceFlinger,SurfaceFlinger根据参数,创建不同类型的Layer,然后调用Layer的setBuffers()方法, 为该Layer创建了两个缓冲区,然后返回该Layer的ISurface接口,SurfaceComposerClient使用这个ISurface接 口创建一个SurfaceControl实例,并把这个SurfaceControl返回给JAVA层。
由此得到以下结果:
- JAVA层的Surface实际上对应于本地层的SurfaceControl对象,以后本地代码可以使用JAVA传入的SurfaceControl对象,通过SurfaceControl的getSurface方法,获得本地Surface对象;
- Android为每个Surface分配了两个图形缓冲区,以便实现Page-Flip的动作;
- 建立SurfaceSession时,SurfaceFlinger创建了用于管理两个图形缓冲区切换的SharedClient对 象,SurfaceComposerClient可以通过ISurfaceFlingerClient接口的getControlBlock()方法获得 这个SharedClient对象,查看SurfaceComposerClient的成员函数_init:
- void SurfaceComposerClient::_init(
- const sp<ISurfaceComposer>& sm, const sp<ISurfaceFlingerClient>& conn)
- {
- ......
- mClient = conn;
- if (mClient == 0) {
- mStatus = NO_INIT;
- return;
- }
-
- mControlMemory = mClient->getControlBlock();
- mSignalServer = sm;
- mControl = static_cast<SharedClient *>(mControlMemory->getBase());
- }
获得Surface对应的显示缓冲区
虽然在SurfaceFlinger在创建Layer时已经为每个Layer申请了两个缓冲区,但是此时在JAVA层并看不到这两个缓冲 区,JAVA层要想在Surface上进行画图操作,必须要先把其中的一个缓冲区绑定到Canvas中,然后所有对该Canvas的画图操作最后都会画到 该缓冲区内。下图展现了绑定缓冲区的过程:
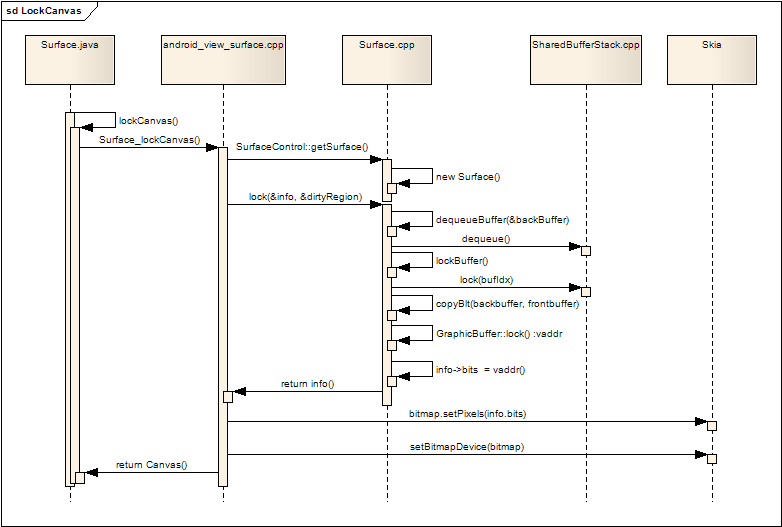
图二 绑定缓冲区的过程
开始在Surface画图前,Surface.java会先调用lockCanvas()来得到要进行画图操作的Canvas,lockCanvas会进 一步调用本地层的Surface_lockCanvas,本地代码利用JAVA层传入的SurfaceControl对象,通过getSurface() 取得本地层的Surface对象,接着调用该Surface对象的lock()方法,lock()返回了改Surface的信息,其中包括了可用缓冲区的 首地址vaddr,该vaddr在Android的2D图形库Skia中,创建了一个bitmap,然后通过Skia库中Canvas的 API:Canvas.setBitmapDevice(bitmap),把该bitmap绑定到Canvas中,最后把这个Canvas返回给JAVA 层,这样JAVA层就可以在该Canvas上进行画图操作,而这些画图操作最终都会画在以vaddr为首地址的缓冲区中。
再看看在Surface的lock()方法中做了什么:
- dequeueBuffer(&backBuffer)获取backBuffer
- SharedBufferClient->dequeue()获得当前空闲缓冲区的编号
- 通过缓冲区编号获得真正的GraphicBuffer:backBuffer
- 如果还没有对Layer中的buffer进行映射(Mapper),getBufferLocked通过ISurface接口重新重新映射
- 获取frontBuffer
- 根据两个Buffer的更新区域,把frontBuffer的内容拷贝到backBuffer中,这样保证了两个Buffer中显示内容的同步
- backBuffer->lock() 获得backBuffer缓冲区的首地址vaddr
- 通过info参数返回vaddr
释放Surface对应的显示缓冲区
画图完成后,要想把Surface的内容显示到屏幕上,需要把Canvas中绑定的缓冲区释放,并且把该缓冲区从变成可投递(因为默认只有两个 buffer,所以实际上就是变成了frontBuffer),SurfaceFlinger的工作线程会在适当的刷新时刻,把系统中所有的 frontBuffer混合在一起,然后通过OpenGL刷新到屏幕上。下图展现了解除绑定缓冲区的过程:

图三 解除绑定缓冲区的过程
- JAVA层调用unlockCanvasAndPost
- 进入本地代码:Surface_unlockCanvasAndPost
- 本地代码利用JAVA层传入的SurfaceControl对象,通过getSurface()取得本地层的Surface对象
- 绑定一个空的bitmap到Canvas中
- 调用Surface的unlockAndPost方法
- 调用GraphicBuffer的unlock(),解锁缓冲区
- 在queueBuffer()调用了SharedBufferClient的queue(),把该缓冲区更新为可投递状态
SharedClient 和 SharedBufferStack
从前面的讨论可以看到,Canvas绑定缓冲区时,要通过SharedBufferClient的dequeue方法取得空闲的缓冲区,而解除绑定 并提交缓冲区投递时,最后也要调用SharedBufferClient的queue方法通知SurfaceFlinger的工作线程。实际上,在 SurfaceFlinger里,每个Layer也会关联一个SharedBufferServer,SurfaceFlinger的工作线程通过 SharedBufferServer管理着Layer的缓冲区,在SurfaceComposerClient建立连接的阶 段,SurfaceFlinger就已经为该连接创建了一个SharedClient 对象,SharedClient 对象中包含了一个SharedBufferStack数组,数组的大小是31,每当创建一个Surface,就会占用数组中的一个 SharedBufferStack,然后SurfaceComposerClient端的Surface会创建一个 SharedBufferClient和该SharedBufferStack关联,而SurfaceFlinger端的Layer也会创建 SharedBufferServer和SharedBufferStack关联,实际上每对 SharedBufferClient/SharedBufferServer是控制着同一个SharedBufferStack对象,通过 SharedBufferStack,保证了负责对Surface的画图操作的应用端和负责刷新屏幕的服务端(SurfaceFlinger)可以使用不 同的缓冲区,并且让他们之间知道对方何时锁定/释放缓冲区。
SharedClient和SharedBufferStack的代码和头文件分别位于:
/frameworks/base/libs/surfaceflinger_client/SharedBufferStack.cpp
/frameworks/base/include/private/surfaceflinger/SharedBufferStack.h
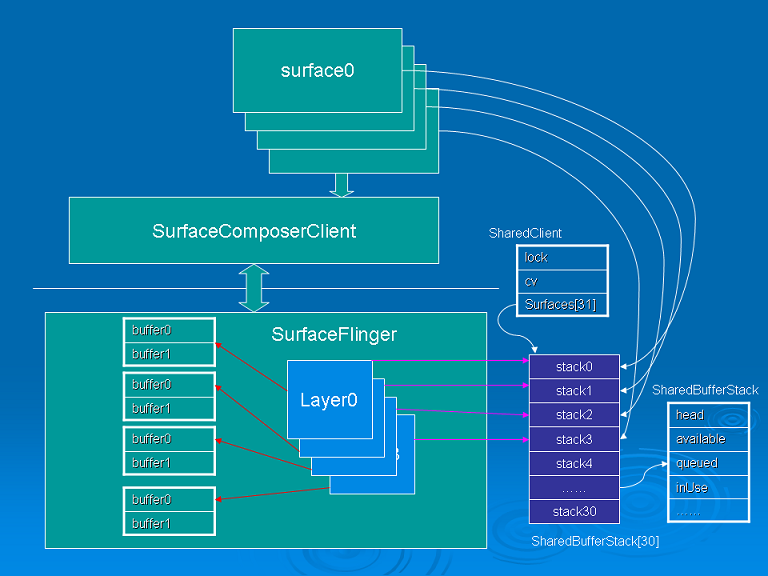
图四 客户端和服务端缓冲区管理
继续研究SharedClient、SharedBufferStack、SharedBufferClient、SharedBufferServer的诞生过程。
1. SharedClient
- 在createConnection阶段,SurfaceFlinger创建Client对象:
- sp<ISurfaceFlingerClient> SurfaceFlinger::createConnection()
- {
- Mutex::Autolock _l(mStateLock);
- uint32_t token = mTokens.acquire();
-
- sp<Client> client = new Client(token, this);
- if (client->ctrlblk == 0) {
- mTokens.release(token);
- return 0;
- }
- status_t err = mClientsMap.add(token, client);
- if (err < 0) {
- mTokens.release(token);
- return 0;
- }
- sp<BClient> bclient =
- new BClient(this, token, client->getControlBlockMemory());
- return bclient;
- }
- 再进入Client的构造函数中,它分配了4K大小的共享内存,并在这块内存上构建了SharedClient对象:
- Client::Client(ClientID clientID, const sp<SurfaceFlinger>& flinger)
- : ctrlblk(0), cid(clientID), mPid(0), mBitmap(0), mFlinger(flinger)
- {
- const int pgsize = getpagesize();
- const int cblksize = ((sizeof(SharedClient)+(pgsize-1))&~(pgsize-1));
-
- mCblkHeap = new MemoryHeapBase(cblksize, 0,
- "SurfaceFlinger Client control-block");
-
- ctrlblk = static_cast<SharedClient *>(mCblkHeap->getBase());
- if (ctrlblk) { // construct the shared structure in-place.
- new(ctrlblk) SharedClient;
- }
- }
- 回到createConnection中,通过Client的getControlBlockMemory()方法获得共享内存块的 IMemoryHeap接口,接着创建ISurfaceFlingerClient的子类BClient,BClient的成员变量mCblk保存了 IMemoryHeap接口指针;
- 把BClient返回给SurfaceComposerClient,SurfaceComposerClient通过 ISurfaceFlingerClient接口的getControlBlock()方法获得IMemoryHeap接口指针,同时保存在 SurfaceComposerClient的成员变量mControlMemory中;
- 继续通过IMemoryHeap接口的getBase ()方法获取共享内存的首地址,转换为SharedClient指针后保存在SurfaceComposerClient的成员变量mControl中;
- 至此,SurfaceComposerClient的成员变量mControl和SurfaceFlinger::Client.ctrlblk指向了同一个内存块,该内存块上就是SharedClient对象。
2. SharedBufferStack、SharedBufferServer、SharedBufferClient
SharedClient对象中有一个SharedBufferStack数组:
SharedBufferStack surfaces[ NUM_LAYERS_MAX ];
NUM_LAYERS_MAX 被定义为31,这样保证了SharedClient对象的大小正好满足4KB的要求。创建一个新的Surface时,进入SurfaceFlinger的 createSurface函数后,先取在createConnection阶段创建的Client对象,通过Client在 0--NUM_LAYERS_MAX 之间取得一个尚未被使用的编号,这个编号实际上就是SharedBufferStack数组的索引:
- int32_t id = client->generateId(pid);
然后以Client对象和索引值以及其他参数,创建不同类型的Layer对象,一普通的Layer对象为例:
- layer = createNormalSurfaceLocked(client, d, id,
- w, h, flags, format);
在createNormalSurfaceLocked中创建Layer对象:
- sp<Layer> layer = new Layer(this, display, client, id);
构造Layer时会先构造的父类LayerBaseClient,LayerBaseClient中创建了SharedBufferServer对 象,SharedBufferStack 数组的索引值和SharedClient被传入SharedBufferServer对象中。
- LayerBaseClient::LayerBaseClient(SurfaceFlinger* flinger, DisplayID display,
- const sp<Client>& client, int32_t i)
- : LayerBase(flinger, display), lcblk(NULL), client(client), mIndex(i),
- mIdentity(uint32_t(android_atomic_inc(&sIdentity)))
- {
- lcblk = new SharedBufferServer(
- client->ctrlblk, i, NUM_BUFFERS,
- mIdentity);
- }
自此,Layer通过lcblk成员变量(SharedBufferServer)和SharedClient共享内存区建立了关联,并且每个Layer对应于SharedBufferStack 数组中的一项。
回到SurfaceFlinger的客户端Surface.cpp中,Surface的构造函数如下:
- Surface::Surface(const sp<SurfaceControl>& surface)
- : mClient(surface->mClient), mSurface(surface->mSurface),
- mToken(surface->mToken), mIdentity(surface->mIdentity),
- mFormat(surface->mFormat), mFlags(surface->mFlags),
- mBufferMapper(GraphicBufferMapper::get()), mSharedBufferClient(NULL),
- mWidth(surface->mWidth), mHeight(surface->mHeight)
- {
- mSharedBufferClient = new SharedBufferClient(
- mClient->mControl, mToken, 2, mIdentity);
-
- init();
- }
SharedBufferClient构造参数mClient->mControl就是共享内存块中的SharedClient对象,mToken就是SharedBufferStack 数组索引值。
到这里我们终于知道,Surface中的mSharedBufferClient成 员和Layer中的lcblk成员(SharedBufferServer),通过SharedClient中的同一个 SharedBufferStack,共同管理着Surface(Layer)中的两个缓冲区。
posted @
2011-10-19 09:05 lfc 阅读(974) |
评论 (0) |
编辑 收藏
参考资料:
1、“Android Display System --- Surface Flinger”
2、“Android核心分析(26) ----- Android GDI之SurfaceFlinger”
3、“Android SurfaceFlinger中的SharedClient -- 客户端(Surface)和服务端(Layer)之间的显示缓冲区管理”
4、“Android SurfaceFlinger中的工作线程:threadLoop()”
一、 surfaceflinger server如何启动:
1、 【System_init.cpp】
extern "C" status_t system_init()
{
……..
char propBuf[PROPERTY_VALUE_MAX];
property_get("system_init.startsurfaceflinger", propBuf, "1");
if (strcmp(propBuf, "1") == 0) {
// Start the SurfaceFlinger
SurfaceFlinger::instantiate(); //实例化
}
……..
}
2、 【SurfaceFlinger.cpp】
void SurfaceFlinger::instantiate() {
defaultServiceManager()->addService(
String16("SurfaceFlinger"), new SurfaceFlinger()); //添加SurfaceFlinger服务
}
3、【Threads.cpp】
int Thread::_threadLoop(void* user)
{
……..
self->mStatus = self->readyToRun();
……..
result = self->threadLoop();
……..
4、【SurfaceFlinger.cpp】
status_t SurfaceFlinger::readyToRun()
{
……..
}
5、【SurfaceFlinger.cpp】
bool SurfaceFlinger::threadLoop()
{
……..
}
二、上层如何与底层SurfaceFlinger建立联系

1、为应用程序创建一个 Client (用于管理和通信)

【SurfaceComposerClient.cpp】
SurfaceComposerClient::SurfaceComposerClient()
{
sp<ISurfaceComposer> sm(getComposerService());
if (sm == 0) {
_init(0, 0);
return;
}
_init(sm, sm->createConnection());
if (mClient != 0) {
Mutex::Autolock _l(gLock);
VERBOSE("Adding client %p to map", this);
gActiveConnections.add(mClient->asBinder(), this);
}
}
注:
经过Binder,最终调用SurfaceFlinger的createConnection实现,这里不作详细介绍,有兴趣请看参考:
“Android 核心分析 之六 -----IPC框架分析 Binder,Service,Service manager”
http://blog.csdn.net/maxleng/article/details/5490770
【SurfaceFlinger.cpp】
sp<ISurfaceFlingerClient> SurfaceFlinger::createConnection()
{
Mutex::Autolock _l(mStateLock);
uint32_t token = mTokens.acquire();
sp<Client> client = new Client(token, this);
if (client->ctrlblk == 0) {
mTokens.release(token);
return 0;
}
status_t err = mClientsMap.add(token, client);
if (err < 0) {
mTokens.release(token);
return 0;
}
sp<BClient> bclient =
new BClient(this, token, client->getControlBlockMemory());
return bclient;
}
2、为这个 Client 分配 Surface(用于存放数据)

【SurfaceComposerClient.cpp】
sp<SurfaceControl> SurfaceComposerClient::createSurface(
int pid,
const String8& name,
DisplayID display,
uint32_t w,
uint32_t h,
PixelFormat format,
uint32_t flags)
{
sp<SurfaceControl> result;
if (mStatus == NO_ERROR) {
ISurfaceFlingerClient::surface_data_t data;
sp<ISurface> surface = mClient->createSurface(&data, pid, name,
display, w, h, format, flags);
if (surface != 0) {
if (uint32_t(data.token) < NUM_LAYERS_MAX) {
result = new SurfaceControl(this, surface, data, w, h, format, flags);
}
}
}
return result;
}
【SurfaceFlinger.cpp】
sp<ISurface> BClient::createSurface(
ISurfaceFlingerClient::surface_data_t* params, int pid,
const String8& name,
DisplayID display, uint32_t w, uint32_t h, PixelFormat format,
uint32_t flags)
{
return mFlinger->createSurface(mId, pid, name, params, display, w, h,
format, flags);
}
sp<ISurface> SurfaceFlinger::createSurface(ClientID clientId, int pid,
const String8& name, ISurfaceFlingerClient::surface_data_t* params,
DisplayID d, uint32_t w, uint32_t h, PixelFormat format,
uint32_t flags)
{
sp<LayerBaseClient> layer;
sp<LayerBaseClient::Surface> surfaceHandle;
if (int32_t(w|h) < 0) {
LOGE("createSurface() failed, w or h is negative (w=%d, h=%d)",
int(w), int(h));
return surfaceHandle;
}
Mutex::Autolock _l(mStateLock);
sp<Client> client = mClientsMap.valueFor(clientId);
if (UNLIKELY(client == 0)) {
LOGE("createSurface() failed, client not found (id=%d)", clientId);
return surfaceHandle;
}
//LOGD("createSurface for pid %d (%d x %d)", pid, w, h);
int32_t id = client->generateId(pid);
if (uint32_t(id) >= NUM_LAYERS_MAX) { //最大支持32个layer
LOGE("createSurface() failed, generateId = %d", id);
return surfaceHandle;
}
switch (flags & eFXSurfaceMask) {
case eFXSurfaceNormal:
if (UNLIKELY(flags & ePushBuffers)) {
layer = createPushBuffersSurfaceLocked(client, d, id,
w, h, flags);
} else {
layer = createNormalSurfaceLocked(client, d, id,
w, h, flags, format);
}
break;
case eFXSurfaceBlur:
layer = createBlurSurfaceLocked(client, d, id, w, h, flags);
break;
case eFXSurfaceDim:
layer = createDimSurfaceLocked(client, d, id, w, h, flags);
break;
}
if (layer != 0) {
layer->setName(name);
setTransactionFlags(eTransactionNeeded);
surfaceHandle = layer->getSurface(); //获取Isurface结构
if (surfaceHandle != 0) { //保存好layer信息
params->token = surfaceHandle->getToken();
params->identity = surfaceHandle->getIdentity();
params->width = w;
params->height = h;
params->format = format;
}
}
return surfaceHandle;
}
sp<LayerBaseClient> SurfaceFlinger::createNormalSurfaceLocked(
const sp<Client>& client, DisplayID display,
int32_t id, uint32_t w, uint32_t h, uint32_t flags,
PixelFormat& format)
{
// initialize the surfaces
switch (format) { // TODO: take h/w into account
case PIXEL_FORMAT_TRANSPARENT:
case PIXEL_FORMAT_TRANSLUCENT:
format = PIXEL_FORMAT_RGBA_8888;
break;
case PIXEL_FORMAT_OPAQUE:
format = PIXEL_FORMAT_RGB_565;
break;
}
sp<Layer> layer = new Layer(this, display, client, id);
status_t err = layer->setBuffers(w, h, format, flags);
if (LIKELY(err == NO_ERROR)) {
layer->initStates(w, h, flags);
addLayer_l(layer);
} else {
LOGE("createNormalSurfaceLocked() failed (%s)", strerror(-err));
layer.clear();
}
return layer;
}
【Layer.cpp】
Layer::Layer(SurfaceFlinger* flinger, DisplayID display,
const sp<Client>& c, int32_t i)
: LayerBaseClient(flinger, display, c, i),
mSecure(false),
mNoEGLImageForSwBuffers(false),
mNeedsBlending(true),
mNeedsDithering(false)
{
// no OpenGL operation is possible here, since we might not be
// in the OpenGL thread.
mFrontBufferIndex = lcblk->getFrontBuffer();
}
【LayerBase.cpp】
LayerBaseClient::LayerBaseClient(SurfaceFlinger* flinger, DisplayID display,
const sp<Client>& client, int32_t i)
: LayerBase(flinger, display), lcblk(NULL), client(client), mIndex(i),
mIdentity(uint32_t(android_atomic_inc(&sIdentity)))
{
lcblk = new SharedBufferServer(
client->ctrlblk, i, NUM_BUFFERS, //建立双buffer
mIdentity);
}
posted @
2011-10-13 16:08 lfc 阅读(6874) |
评论 (0) |
编辑 收藏Android GDI之SurfaceFlinger
SurfaceFinger按英文翻译过来就是Surface投递者。SufaceFlinger的构成并不是太复杂,复杂的是他的客户端建构。SufaceFlinger主要功能是:
1) 将Layers (Surfaces) 内容的刷新到屏幕上
2) 维持Layer的Zorder序列,并对Layer最终输出做出裁剪计算。
3) 响应Client要求,创建Layer与客户端的Surface建立连接
4) 接收Client要求,修改Layer属性(输出大小,Alpha等设定)
但是作为投递者的实际意义,我们首先需要知道的是如何投递,投掷物,投递路线,投递目的地。
1 SurfaceFlinger的基本组成框架

SurfaceFlinger管理对象为:
mClientsMap:管理客户端与服务端的连接。
ISurface,IsurfaceComposer:AIDL调用接口实例
mLayerMap:服务端的Surface的管理对象。
mCurrentState.layersSortedByZ :以Surface的Z-order序列排列的Layer数组。
graphicPlane 缓冲区输出管理
OpenGL ES:图形计算,图像合成等图形库。
gralloc.xxx.so这是个跟平台相关的图形缓冲区管理器。
pmem Device:提供共享内存,在这里只是在gralloc.xxx.so可见,在上层被gralloc.xxx.so抽象了。
2 SurfaceFinger Client和服务端对象关系图

Client端与SurfaceFlinger连接图:

Client对象:一般的在客户端都是通过SurfaceComposerClient来跟SurfaceFlinger打交道。


3 主要对象说明
3.1 DisplayHardware &FrameBuffer
首先SurfaceFlinger需要操作到屏幕,需要建立一个屏幕硬件缓冲区管理框架。Android在设计支持时,考虑多个屏幕的情况,引入了 graphicPlane的概念。在SurfaceFlinger上有一个graphicPlane数组,每一个graphicPlane对象都对应一个 DisplayHardware.在当前的Android(2.1)版本的设计中,系统支持一个graphicPlane,所以也就支持一个 DisplayHardware。
SurfaceFlinger,Hardware硬件缓冲区的数据结构关系图。

3.2 Layer

method:setBuffer 在SurfaceFlinger端建立显示缓冲区。这里的缓冲区是指的HW性质的,PMEM设备文件映射的内存。
1) layer的绘制
void Layer::onDraw(const Region& clip) const
{
int index = mFrontBufferIndex;
GLuint textureName = mTextures[index].name;
…
drawWithOpenGL(clip, mTextures[index]);
}
3.2 mCurrentState.layersSortedByZ
以Surface的Z-order序列排列的LayerBase数组,该数组是层显示遮挡的依据。在每个层计算自己的可见区域时,从Z-order 顶层开始计算,是考虑到遮挡区域的裁减,自己之前层的可见区域就是自己的不可见区域。而绘制Layer时,则从Z-order底层开始绘制,这个考虑到透 明层的叠加。
4 SurfaceFlinger的运行框架
我们从前面的章节<Android Service>的基本原理可以知道,SurfaceFlinger的运行框架存在于:threadLoop,他是SurfaceFlinger的主循环体。SurfaceFlinger在进入主体循环之前会首先运行:SurfaceFlinger::readyToRun()。
4.1 SurfaceFlinger::readyToRun()
(1)建立GraphicPanle
(2)建立FrameBufferHardware(确定输出目标)
初始化:OpenGL ES
建立兼容的mainSurface.利用eglCreateWindowSurface。
建立OpenGL ES进程上下文。
建立主Surface(OpenGL ES)。 DisplayHardware的Init()@DisplayHardware.cpp函数对OpenGL做了初始化,并创建立主Surface。为什 么叫主Surface,因为所有的Layer在绘制时,都需要先绘制在这个主Surface上,最后系统才将主Surface的内容”投掷”到真正的屏幕 上。
(3) 主Surface的绑定
1)在DisplayHandware初始完毕后,hw.makeCurrent()将主Surface,OpenGL ES进程上下文绑定到SurfaceFlinger的上下文中,
2)之后所有的SurfaceFlinger进程中使用EGL的所有的操作目的地都是mSurface@DisplayHardware。
这样,在OpenGL绘制图形时,主Surface被记录在进程的上下文中,所以看不到显示的主Surfce相关参数的传递。下面是Layer-Draw,Hardware.flip的动作示意图:

4.2 ThreadLoop

(1)handleTransaction(…):主要计算每个Layer有无属性修改,如果有修改着内用需要重画。
(2)handlePageFlip()
computeVisibleRegions:根据Z-Order序列计算每个Layer的可见区域和被覆盖区域。裁剪输出范围计算-
在生成裁剪区域的时候,根据Z_order依次,每个Layer在计算自己在屏幕的可显示区域时,需要经历如下步骤:
1)以自己的W,H给出自己初始的可见区域
2)减去自己上面窗口所覆盖的区域

在绘制时,Layer将根据自己的可将区域做相应的区域数据Copy。
(3)handleRepaint()
composeSurfaces(需要刷新区域):
根据每个Layer的可见区域与需要刷新区域的交集区域从Z-Order序列从底部开始绘制到主Surface上。
(4)postFramebuffer()
(DisplayHardware)hw.flip(mInvalidRegion);
eglSwapBuffers(display,mSurface) :将mSruface投递到屏幕。
5 总结
现在SurfaceFlinger干的事情利用下面的示意图表示出来:

posted @
2011-10-13 15:08 lfc 阅读(996) |
评论 (0) |
编辑 收藏
摘要: SurfaceFlinger 是Android multimedia 的一个部分,在Android 的实现中它是一个service ,提供系统 范围内的surface composer 功能,它能够将各种应用 程序的2D 、3D surface 进行组合。在具体讲SurfaceFlinger 之前,我们先来看一下有关显示方面的一些基础 ...
阅读全文
posted @
2011-08-10 09:38 lfc 阅读(3266) |
评论 (0) |
编辑 收藏介绍 本文档对Android RIL部分的内容进行了介绍,其重点放在了Android RIL的原生代码部分。包括四个主题:
1.Android RIL框架介绍
2.Android RIL与 WindowsMobile RIL
3.Android RIL porting
4.Android RIL的java框架
在本文档中将Android代码中的重要模块列出进行分析,并给出了相关的程序执行流程介绍,以加深对模块间交互方式的理解。
对于java代码部分,这里仅进行简单的介绍。如果需要深入了解,可以查看相关参考资料。
本文档中还对Android RIL的Porting部分内容进行了描述和分析。
针对对unix操作系统环境并不熟悉的读者,本文档中所涉及到的相关知识包括:
Unix file system
Unix socket
Unix thread
Unix 下I/O多路转接
以上信息可以在任意一份描述Unix系统调用的文档中找到。
1.Android RIL框架介绍 术语: fd unix文件描述符
pipe unix管道
cond 一般是condition variable的缩写
tty 通常使用tty来简称各种类型的终端设备
unsolicited response 被动请求命令来自baseband
event loop android的消息队列机制,由unix的系统调用select()实现
init.rc init守护进程启动后被执行的启动脚本。
HAL 硬件抽象层(Hardware Abstraction Layer,HAL)
1.1.Android RIL概况: Android RIL提供了无线硬件设备与电话服务之间的抽象层。
下图展示了RIL在Android体系中的位置。

android的ril位于应用程序框架与内核之间,分成了两个部分,一个部分是rild,它负责socket与应用程序框架进行通信。另外一个部分是Vendor RIL,这个部分负责向下是通过两种方式与radio进行通信,它们是直接与radio通信的AT指令通道和用于传输包数据的通道,数据通道用于手机的上网功能。
对于RIL的java框架部分,也被分成了两个部分,一个是RIL模块,这个模块主要用于与下层的rild进行通信,另外一个是Phone模块,这个模块直接暴露电话功能接口给应用开发用户,供他们调用以进行电话功能的实现。
1.2.Android RIL目录结构: Android的RIL模块位于Android/hardware/ril文件夹,有三个子模块:rild , libril , reference-ril
●include文件夹:
包含RIL头文件,最主要的是ril.h
●rild文件夹:
RIL守护进程,开机时被init守护进程调用启动,里面仅有main函数作为入口点,负责完成RIL初始化工作。
在rild.c文件中,将完成ril的加载过程,它会执行如下操作:
动态加载Vendor RIL的.so文件
执行RIL_startEventLoop()开启消息队列以进行事件监听
通过执行Vendor RIL的rilInit()方法来进行Vendor RIL与libril的关系建立。
在rild文件夹中还包括一个radiooptions.c文件,它的作用是通过串口将一些radio相关的参数直接传给rild来对radio进行配置。
●libril文件夹:
在编译时libril被链入rild,它为rild提供了event处理功能,还提供了在rild与Vendor RIL之间传递请求和响应消息的能力。
Libril提供的主要功能分布在两个主要方法内,一个是RIL_startEventLoop()方法,另一个是RIL_register()方法
RIL_startEventLoop()方法所提供的功能就是启用eventLoop线程,开始执行RIL消息队列。
RIL_register()方法的主要功能是启动名为 rild 的监听端口,等待java 端通过socket进行连接。
●reference-ril文件夹:
Android自带的Vendor RIL的参考实现。被编译成.so文件,由于本部分是厂商定制的重点所在。所以被设计为松散耦合,且可灵活配置的。在rild中通过opendl()的方式加载。
librefrence.so负责直接与radio通信,这包括将来自libril的指令转换为AT指令,并且将AT指令写入radio中。
reference-ril会接收调用者传来的参数,参数内容为与radio的通信方式。如通过串口连接radio,那么参数为这种形式:-d /dev/ttySx
1.3.Android RIL中的消息(event)队列机制: 在Android RIL中,为了达到等待多路输入并且不出现阻塞的目的,使用了IO多路复用机制。
如果使用阻塞I/O进行网络的读取写入,这意味着假如需要同时从两个网络文件描述符中读内容,那么如果读取操作在等待网络数据到来,这将可能很长时间阻塞在一个描述符上,另一个网络文件描述符不管有没有数据到来都无法被读取。
一种解决方案是:
如果使用非阻塞I/O进行网络的读取写入,在读取其中一个网络文件描述符如果阻塞将直接返回,再读取另外一个,这种方式的循环被称之为轮询。轮询方式确实能解决进行多路io操作时的阻塞问题,但是这种方法的不足之处是反复的执行读写调用将浪费cpu时钟。
I/O多路转接技术在这里提供了另一种比较好的解决方案:
它会先构造一张有关I/O描述符的列表,然后调用select函数,当IO描述符列表中的一个描述符准备好进行I/O时,该函数返回,并告知可以读或写哪个描述符。
Android RIL中消息队列的核心实现思想就是这种I/O多路转接技术。
消息队列机制的实现在ril_event.cpp中,其中被定义的ril_event结构是消息的主体。
每个ril_event结构,与一个fd句柄绑定(可以是文件,socket,管道等),并且带一个func指针,这个func指针所指的函数是个回调函数,它指定了当所绑定的fd准备好进行读取时所要进行的操作。
消息队列的开始点为RIL_startEventLoop函数。RIL_startEventLoop在ril.cpp中实现,它的主要目的是通过pthread_create(&s_tid_dispatch, &attr, eventLoop, NULL)建立一个dispatch线程,线程入口点在eventLoop. 而在eventLoop中,会调ril_event.cpp中的ril_event_loop()函数,建立起消息队列机制。
ril_event是一个带有链表行为的struct,它最主要的成员一个是fd,一个是func:
struct ril_event {
struct ril_event *next;
struct ril_event *prev;
int fd;
int index;
bool persist;
struct timeval timeout;
ril_event_cb func;
void *param;
};
初始化一个新ril_event的操作是通过ril_event_set()来完成的,并通过ril_event_add()加入到消息队列之中,add会把队列里所有ril_event的fd,放入一个fd集合readFds中。这样 ril_event_loop能通过一个多路复用I/O的机制(select)来等待这些fd。
在进入ril_event_loop()之前,在eventLoop中已经创建和挂入了s_wakeupfd_event,它是通过pipe的机制实现的,这个管道fd的回调函数并没有实现什么功能,它的目的只是为了让select方法能返回一次,这样select()方法就能重新跟踪新加入事件队列的fd和timeout设置。
所以在添加新fd到eventLoop时,往往不是直接调用ril_event_add,实际通常用rilEventAddWakeup来添加,这个方法除了会间接调用ril_event_add外,还会调用triggerEvLoop()函数来向s_fdWakeupWrite中写入一个空字符,这样select()函数会返回并重新执行,新加入的文件描述符便得以被select()加载并跟踪。
如果在ril_event队列中任何一个fd已经准备好,则进入分析流程:
processTimeouts(),processReadReadies(&rfds, n),firePending()
其中firePending()方法执行这个event的func,也就是回调函数。
在Android RIL初始化完成后,将有几个event被挂入到eventLoop中:
1. s_listen_event: 名为rild的socket,主要requeset & response通道
2. s_debug_event: 名为rild-debug的socket,调试用requeset & response通道
3. s_wakeupfd_event: 无名管道,用于队列主动唤醒
这其中最为重要的event就是s_listen_event,它作为request与response的通道实现。
在ril_event.cpp中还持有一个watch_table数组,一个timer_list链表和一个pending_list链表。
watch_table数组的目的很单纯,存放当前被eventLoop等待的ril_event(非timer event),供eventLoop唤醒时使用。
timer_list是存放timer event的链表,在eventLoop唤醒时要对这些timer event单独进行处理
pending_list:待处理(对其回调函数进行调用)的所有ril_event的链表。
1.4.Android RIL中初始化流程分析:
● Rild的初始化流程
初始化流程从rild.c中的main函数开始,它被init守护进行调用执行:
首先在main()函数内会首先通过dlopen()函数加载Vendor RIL(在自带的参考实现中为librefrence_ril.so)。接着调用RIL_startEventLoop()函数来启动消息队列机制。
调用librefrence_ril.so的RIL_Init()函数来进行Vendor RIL的初始化。RIL_Init()函数执行后会返回一个RIL_RadioFunction结构体,这个结构体内最重要的成员就是onRequest()方法。onRequest()方法会被dispatchFunction调用,也就是说dispatchFunction调用是程序流从rild转入Vendor RIL的分界点。
RIL_register()函数将实现两个目地,一个是将RIL_INIT中获得的RIL_RadioFunction进行注册,rild通过此种方式保证自己持有一个RIL_RadioFunction实例,第二个是将s_fdListen加入到消息队列机制中,开启s_fdListen的事件监听。
● Vendor RIL的初始化流程:
RIL_Init被调用后首先通过参数获取硬件接口的设备文件或模拟硬件接口的socket。(参见上文中对reference-ril文件夹的介绍)
接下来是创建mainLoop线程,并跳入到线程内执行。mainLoop会建立起与硬件的通信,然后通过read方法阻塞等待硬件的主动上报或响应。mainLoop还会调用initlizeCallBack()函数来向radio发送一系列的AT命令来进行radio的初始化设置工作。
1.5.Android RIL中request流程分析: 上层应用开始向rild通过socket传输数据时,通过RIL消息队列机制,s_listen_event的回调函数listenCallBack将会被调用,开始进行数据流的分析与处理。
接下来,s_fdCommand = accept(s_fdListen, (sockaddr *) &peeraddr, &socklen),获取传入的socket描述符,也就是上层的java RIL传入的连接。
然后,通过record_stream_new()建立起一个RecordStream, 将这个record_stream与s_fdCommand绑定, RecordStream实际上是一个用于存放数据的结构体,这个结构体提供了一些操作类来保证这个RecordStream所绑定的文件描述符被读取时里面的数据会被完整读取。
一旦s_fdCommand中有数据,它的回调函数processCommandsCallback()将会被调用,processCommandsCallback()通过record_stream_get_next阻塞读取s_fdCommand上发来的 数据, 直到收到一完整的request。然后将其传递进processCommandBuffer()函数,processCommandBuffer()正式进入了命令的解析部分。
每个接收到的命令将以RequestInfo的形式存在。从socket过来的数据流,是Parcel处理过的序列化字节流, 在这里会通过反序列化的方法提取出来。最前面的是request号, 以及token域(request的递增序列号)。request号是一个CommandInfo,它在ril_command.h中定义。
接下来, 这个RequestInfo会被挂入pending的request队列, 执行具体的dispatchFunction(), 进行详细解析。
dispatchFunction方法有着多种实现,如dispatchVoid, dispatchString, 它们的调用取决于Parcel的参数传入形式。比如说在dispatchDial方法中,Parcel对象将被解析为RIL_Dial结构。这是disptachFunction的任务之一,它的另一个任务就是调用onRequest()方法,并将解析的内容传入onRequest()方法。
从onRequest方法开始,程序控制流脱离了RILD,进入到了Vendor RIL中。
onRequest方法会通过传入的请求类型来调用指定的request×××()方法,request×××()方法则负责组装AT指令并下发给at_send_command()方法集合中的一个,这个方法集合提供了针对不同类型AT指令的实现,如单行AT指令at_send_command_singleline(),短信息指令at_send_command_sms()等。
最后,执行at_send_command_full(),再通过一个互斥的at_send_command_full_nolock()调用,完成最终的写出操作,在writeline()中,写出到初始化时打开的设备中。
需要注意的是:at_send_command_full_nolock()在将指令写入radio后并不会直接返回,而是通过条件变量等待响应信息,得到响应信息后会携带这些信息返回。具体流程可以参考下面的response流程分析。
1.6.Android RIL中response流程分析: AT的response有两种,一种是unsolicited。另一种是普通response,也就是命令的响应。
response信息的获取在readerLoop()中。由readline()函数读取上来。
读取到的line将被传入processLine()函数进行解析,processLine()函数首先会判断当前的响应是主动响应还是普通响应,如果是主动响应,将调用handleUnsolicited()函数,如果为普通响应,那么将调用handleFinalResponse()函数进行处理
对响应串的主要的解析过程,由at_tok.c中的各种解析函数完成,提供字符串分析解析功能。
● 对主动上报的解析
handleUnsolicited ()方法处理主动上报,它会调用onUnsolicited()来进行进一步的解析,这个函数在Vendor-RIL初始化时被传入at_open()函数,onUnsolicited只解析出头部(一般是+XXXX的形式),然后按类型决定下一步操作,操作为 RIL_onUnsolicitedResponse和RIL_requestTimedCallback两种。
在RIL_onUnsolicitedResponse()函数中,通过Parcel传递,将 RESPONSE_UNSOLICITED,unsolResponse(request号)写入Parcel,然后调用对应的responseFunction完成进一步的的解析,将解析的数据写入Parcel中,最后通过sendResponse()→sendResponseRaw()→blockingWrite()→writeLine()将数据写回给与应用层通信的socket。
在RIL_requestTimedCallback()函数中。通过event机制实现的timer机制,回调对应的内部处理函数。通过internalRequestTimedCallback将回调添加到event循环,最终完成callback上挂的函数的回调。比如 pollSIMState,onPDPContextListChanged等回调, 不用返回上层,内部处理就可以。
● 对普通上报的解析
IsFinalResponse()和isFinalResponseError()所处理的是一条AT指令的响应上报,它们将转入handleFinalResponse方法。
handleFinalResponse()函数会将所有响应信息装入sp_response,这是一个ATResponse结构,它的成员包括成功与否(success)以及一个中间结果(p_intermediates)。
handleFinalResponse()在将响应结果保存至sp_response后, 设置s_commandcond这一条件变量,此条件变量由at_send_command_full_nolock等待。
at_send_command_full_nolock获得到了完整的响应信息(在sp_response中),便开始进行响应信息的处理,最后由RIL_onRequestComplete将响应数据序列化并通过sendResponse传递至与应用层通信的socket,这一部分与RIL_onUnsolicitedResponse()函数的功能非常相似,请参考对主动上报的解析部分。
2.Android RIL与 WindowsMobile RIL Android RIL与WindowsMobile RIL 在设计思路上都是作为一个radio的抽象,为上层提供电话服务,但在实现方式上两者有着一定的差异,这种差异的产生主要是源自操作系统机制的不同。
Android RIL被实现为HAL,相对于windows mobile中被实现为驱动的方式,Android RIL模块的内聚性更为理想,可维护性也将更强,你也可以把Android Ril 看做一个中间件。Android RIL部分的开发工作,只需要拿到相应的radio文件描述符,就可以进行操作,无需关注radio的I/O驱动实现。
2.1两者在与应用通信上的实现对比
WindowsMobile RIL在实现与应用的通信时提供了RIL Proxy,在这个层面中它定义了大量的RIL_***()函数来作为电话服务请求。这一点与Android RIL的实现比较相似,Android RIL中在ril.h内提供了一系列的宏来定义电话服务请求。
在Android中的rild功能类似于windows mobile RIL的RIL proxy。它同样也是起到一个中介的作用,为上层接口向下传递请求,并上传回响应。在windows mobile RIL中要为每一个应用程序客户提供一份Ril Proxy实例。
对于这两种操作系统平台,RIL所定义的所有请求是不可更改的。
2.2两者在线程结构与回调机制上的对比
在windows mobile的设计中,request与response被设计为异步执行的,他们分别使用两个队列来对它们的异步行为进行管理,执行命令下发和上报命令处理的过程也互不影响,下发命令与命令的相应响应之间的依赖关系由应用程序来捏合。
在android ril中的request与response设计与windows mobile不同,它的命令与响应之间是同步的过程。也就是说一条命令被下发后,将等待执行结果,并进行处理,再上向上层发。而不是直接异步的进行处理和向上发送。
3.Android RIL porting 3.1.命名 要实现某个无线模块的RIL,需要创建一个实现了所有请求方法的共享库,保证Android能够响应无线通信请求。所有的请求被定义ril.h中。
不同的Modem使用不同的端口,这个在init.rc中设置。
Android提供了一个参考Vendor RIL,RIL参考源码在reference-ril。
将你自己的Vendor RIL实现编译为共享库形式:
libril-<companyname>-<RIL version>.so
比如:
libril-techfaith-124.so
其中:
libril:所有vendor RIL的开头
<companyname>:公司缩写
<RIL version>:RIL版本number
so:文件扩展
3.2.Android RIL的配置与加载 在init.rc文件中,将通过这种方式来进行Android RIL的加载。
service ril-daemon /system/bin/rild -l /system/lib/libreference-ril.so -- -d /dev/ttyS0
也可以手动加载:
/system/bin/rild -l /system/lib/libreference-ril.so -- -d /dev/ttyS0
这两种方式,都将启动rild守护进程,然后通过-l参数将libreference-ril.so共享库链入,libreference-ril.so的参数-d是指加载一个串口设备,/dev/ttyS0则是这个串口设备的具体设备文件,除了参数-d外,还有-s代表加载类型为socket的设备,-p代表回环接口。
3.3.Android RIL的编译结构 rild:
被编译成可执行文件,rild以守进程的形式执行。
libril:
将被编译为共享库,并被链入rild。
Vendor RIL:
可以以两种方式来运行,如果定义了RIL_SHLIB宏,那么它将被编译成共享库,如果没定义RIL_SHLIB宏,它将以守护进程程序的方式被调用执行。
4.Android RIL的java框架
Android RIL的Java部分也被分为了两个模块,RIL模块与Phone模块。其中RIL模块负责进行请求以及相应的处理,它将直接与RIL的原声代码进行通信。而Phone模块则向应用程序开发者提供了一系列的电话功能接口。
4.1.RIL模块结构
在RIL.java中实现了几个类来进行与下层rild的通信。
它实现了如下几个类来完成操作:
RILRequest:代表一个命令请求
RIL.RILSender:负责AT指令的发送
RIL.RILReceiver:用于处理主动和普通上报信息
RIL.RILSender与RIL.RILReceiver是两个线程。
RILRequest提供了obtain()方法,用于得到具体的request操作,这些操作被定义在RILConstants.java中(RILConstants.java中定义的request命令与RIL原生代码中ril.h中定义的request命令是相同的),然后通过send()函数发送EVENT_SEND,在RIL_Sender线程中处理这个EVENT_SEND将命令写入到stream(socket)中去。Socket是来自常量SOCKET_NAME_RIL,它与RIL 原生代码部分的s_fdListen所指的socket是同一个。
当有上报信息来到时,系统将通过RILReciver来得到信息,并进行处理。在RILReciver的生命周期里,它一直监视着SOCKET_NAME_RIL这个socket,当有数据到来时,它将通过readRilMessage()方法读取到一个完整的响应,然后通过processResponse来进行处理。
4.2.Phone模块结构
Android通过暴露Phone模块来供上层应用程序用户使用电话功能相关的接口。它为用户提供了诸如电话呼叫,短信息,SIM卡管理之类的接口调用。它的核心部分是类GSMPhone,这个是Gsm的电话实现,需要通过PhoneFactory获取这个GSMPhone。
GSMPhone并不是直接提供接口给上层用户使用,而是通过另外一个管理类TelephonyManager来供应用程序用户使用。
类TelephonyManager实现了android的电话相关操作。它主要使用两个服务来访问telephony功能:
1.ITelephony,提供给上层应用程序用户与telephony进行操作,交互的接口,在packages/apps/Phone中由PhoneInterfaceManager.java实现。
2.ItelephonyRegistry提供了一个通知机制,将底层来的上报通知给框架中需要得到通知的部分,由TelephonyRegistry.java实现。
GSMPhone通过PhoneNotifier的实现者DefaultPhoneNotifier将具体的事件转化为函数调用,通知到TelephonyRegistry。TelephonyRegistry再通过两种方式通知给用户,其一是广播事件,另外一种是通过服务用户在TelephonyRegistry中注册的IphoneStateListener接口,实现回调(回调方式参见android的aidl机制)。
参考资料
相关网站:
http://code.google.com/android/
http://android-dls.com
http://www.ibm.com/developerworks/cn/opensource/theme/android/
http://en.wikipedia.org/wiki/Android_%28operating_system%29
相关书籍:
《UNIX环境高级编程》
《UNIX编程艺术》
《Android系统原理及开发要点详解》
posted @
2011-05-28 14:31 lfc 阅读(11992) |
评论 (0) |
编辑 收藏文章作者:Slyar 文章来源:Slyar Home (www.slyar.com) 转载请注明,谢谢合作。
恩,问这个问题的人太多了,懒得继续回答,直接贴上来自己看。。。
|
优先级
|
运算符
|
名称或含义
|
使用形式
|
结合方向
|
说明
|
|
1
|
[]
|
数组下标
|
数组名[常量表达式]
|
左到右
|
|
|
()
|
圆括号
|
(表达式)/函数名(形参表)
|
|
|
.
|
成员选择(对象)
|
对象.成员名
|
|
|
->
|
成员选择(指针)
|
对象指针->成员名
|
|
|
2
|
-
|
负号运算符
|
-表达式
|
右到左
|
单目运算符
|
|
(类型)
|
强制类型转换
|
(数据类型)表达式
|
|
|
++
|
自增运算符
|
++变量名/变量名++
|
单目运算符
|
|
--
|
自减运算符
|
--变量名/变量名--
|
单目运算符
|
|
*
|
取值运算符
|
*指针变量
|
单目运算符
|
|
&
|
取地址运算符
|
&变量名
|
单目运算符
|
|
!
|
逻辑非运算符
|
!表达式
|
单目运算符
|
|
~
|
按位取反运算符
|
~表达式
|
单目运算符
|
|
sizeof
|
长度运算符
|
sizeof(表达式)
|
|
|
3
|
/
|
除
|
表达式/表达式
|
左到右
|
双目运算符
|
|
*
|
乘
|
表达式*表达式
|
双目运算符
|
|
%
|
余数(取模)
|
整型表达式/整型表达式
|
双目运算符
|
|
4
|
+
|
加
|
表达式+表达式
|
左到右
|
双目运算符
|
|
-
|
减
|
表达式-表达式
|
双目运算符
|
|
5
|
<<
|
左移
|
变量<<表达式
|
左到右
|
双目运算符
|
|
>>
|
右移
|
变量>>表达式
|
双目运算符
|
|
6
|
>
|
大于
|
表达式>表达式
|
左到右
|
双目运算符
|
|
>=
|
大于等于
|
表达式>=表达式
|
双目运算符
|
|
<
|
小于
|
表达式<表达式
|
双目运算符
|
|
<=
|
小于等于
|
表达式<=表达式
|
双目运算符
|
|
7
|
==
|
等于
|
表达式==表达式
|
左到右
|
双目运算符
|
|
!=
|
不等于
|
表达式!= 表达式
|
双目运算符
|
|
8
|
&
|
按位与
|
表达式&表达式
|
左到右
|
双目运算符
|
|
9
|
^
|
按位异或
|
表达式^表达式
|
左到右
|
双目运算符
|
|
10
|
|
|
按位或
|
表达式|表达式
|
左到右
|
双目运算符
|
|
11
|
&&
|
逻辑与
|
表达式&&表达式
|
左到右
|
双目运算符
|
|
12
|
||
|
逻辑或
|
表达式||表达式
|
左到右
|
双目运算符
|
|
13
|
?:
|
条件运算符
|
表达式1? 表达式2: 表达式3
|
右到左
|
三目运算符
|
|
14
|
=
|
赋值运算符
|
变量=表达式
|
右到左
|
|
|
/=
|
除后赋值
|
变量/=表达式
|
|
|
*=
|
乘后赋值
|
变量*=表达式
|
|
|
%=
|
取模后赋值
|
变量%=表达式
|
|
|
+=
|
加后赋值
|
变量+=表达式
|
|
|
-=
|
减后赋值
|
变量-=表达式
|
|
|
<<=
|
左移后赋值
|
变量<<=表达式
|
|
|
>>=
|
右移后赋值
|
变量>>=表达式
|
|
|
&=
|
按位与后赋值
|
变量&=表达式
|
|
|
^=
|
按位异或后赋值
|
变量^=表达式
|
|
|
|=
|
按位或后赋值
|
变量|=表达式
|
|
|
15
|
,
|
逗号运算符
|
表达式,表达式,…
|
左到右
|
从左向右顺序运算
|
说明:
同一优先级的运算符,运算次序由结合方向所决定。
简单记就是:! > 算术运算符 > 关系运算符 > && > || > 赋值运算符
posted @
2010-08-26 21:54 lfc 阅读(1496) |
评论 (5) |
编辑 收藏------------------------------------------
出处: http://ericxiao.cublog.cn/
------------------------------------------
一:前言
Serio总线同之前分析的platform总线一样,也是一种虚拟总线。它是Serial I/O的输写,表示串行的输入输出设备.很多输入输出设备都是以此为基础的。同前面几篇笔记一样,下面的代码分析是基于linux kernel 2.6.25版本.
二:serio总线的初始化
Serio总线的初始化是在linux2.6.25/drivers/input/serio/serio.c中完成的。代码如下:
static int __init serio_init(void)
{
int error;
error = bus_register(&serio_bus);
if (error) {
printk(KERN_ERR "serio: failed to register serio bus, error: %d\n", error);
return error;
}
serio_task = kthread_run(serio_thread, NULL, "kseriod");
if (IS_ERR(serio_task)) {
bus_unregister(&serio_bus);
error = PTR_ERR(serio_task);
printk(KERN_ERR "serio: Failed to start kseriod, error: %d\n", error);
return error;
}
return 0;
}
在这里,创建了对应bus_type为serio_bus的总线。还创建了一个名为“kseriod”的内核线程。我们暂且不管它是做什么的。等以后的代码涉及到再来进行分析。
三:serio设备注册
Serio设备对应的数据结构为struct serio.对应的注册接口为:serio_register_port().代码如下:
static inline void serio_register_port(struct serio *serio)
{
__serio_register_port(serio, THIS_MODULE);
}
它是__serio_register_port()的一个封装函数。代码如下:
void __serio_register_port(struct serio *serio, struct module *owner)
{
serio_init_port(serio);
serio_queue_event(serio, owner, SERIO_REGISTER_PORT);
}
它先初始化一个serio设备。在serio_init_port()中,它指定了设备的总线类型为serio_bus.之后,调用serio_queue_event().看这个函数的名称好像是产生了什么事件。来看一下它的代码。
static int serio_queue_event(void *object, struct module *owner,
enum serio_event_type event_type)
{
unsigned long flags;
struct serio_event *event;
int retval = 0;
spin_lock_irqsave(&serio_event_lock, flags);
/*
* Scan event list for the other events for the same serio port,
* starting with the most recent one. If event is the same we
* do not need add new one. If event is of different type we
* need to add this event and should not look further because
* we need to preseve sequence of distinct events.
*/
list_for_each_entry_reverse(event, &serio_event_list, node) {
if (event->object == object) {
if (event->type == event_type)
goto out;
break;
}
}
event = kmalloc(sizeof(struct serio_event), GFP_ATOMIC);
if (!event) {
printk(KERN_ERR
"serio: Not enough memory to queue event %d\n",
event_type);
retval = -ENOMEM;
goto out;
}
if (!try_module_get(owner)) {
printk(KERN_WARNING
"serio: Can't get module reference, dropping event %d\n",
event_type);
kfree(event);
retval = -EINVAL;
goto out;
}
event->type = event_type;
event->object = object;
event->owner = owner;
list_add_tail(&event->node, &serio_event_list);
wake_up(&serio_wait);
out:
spin_unlock_irqrestore(&serio_event_lock, flags);
return retval;
}
这个函数比较简单。就是根据参数信息生成了一个struct serio_event结构。再将此结构链接至serio_event_list末尾。
接着就要来寻找serio_event_list这个链表的处理了。这个就是serio_thread的工作了。还记得初始化的时候所创建的线程么。不错,就是它。Kernel可能认为对serio的操作比较频繁。所以对一些操作事件化,将它以多线程处理。
serio_thread()代码如下:
static int serio_thread(void *nothing)
{
set_freezable();
do {
serio_handle_event();
wait_event_freezable(serio_wait,
kthread_should_stop() || !list_empty(&serio_event_list));
} while (!kthread_should_stop());
printk(KERN_DEBUG "serio: kseriod exiting\n");
return 0;
}
这个函数的核心处理是serio_handle_event().代码如下:
static void serio_handle_event(void)
{
struct serio_event *event;
mutex_lock(&serio_mutex);
/*
* Note that we handle only one event here to give swsusp
* a chance to freeze kseriod thread. Serio events should
* be pretty rare so we are not concerned about taking
* performance hit.
*/
if ((event = serio_get_event())) {
switch (event->type) {
case SERIO_REGISTER_PORT:
serio_add_port(event->object);
break;
case SERIO_RECONNECT_PORT:
serio_reconnect_port(event->object);
break;
case SERIO_RESCAN_PORT:
serio_disconnect_port(event->object);
serio_find_driver(event->object);
break;
case SERIO_ATTACH_DRIVER:
serio_attach_driver(event->object);
break;
default:
break;
}
serio_remove_duplicate_events(event);
serio_free_event(event);
}
mutex_unlock(&serio_mutex);
}
这个函数的流程大致是这样的:
调用serio_get_event()从链表中取出struct serio_event元素,然后对这个元素的事件类型做不同的时候,处理完了之后,调用serio_remove_duplicate_events()在链表中删除相同请求的event.
对应之前的serio_register_port()函数,它产生的事件类型是SERIO_REGISTER_PORT.也就是说,对于注册serio设备来说,流程会转入serio_add_port().
代码如下:
static void serio_add_port(struct serio *serio)
{
int error;
if (serio->parent) {
serio_pause_rx(serio->parent);
serio->parent->child = serio;
serio_continue_rx(serio->parent);
}
list_add_tail(&serio->node, &serio_list);
if (serio->start)
serio->start(serio);
error = device_add(&serio->dev);
if (error)
printk(KERN_ERR
"serio: device_add() failed for %s (%s), error: %d\n",
serio->phys, serio->name, error);
else {
serio->registered = 1;
error = sysfs_create_group(&serio->dev.kobj, &serio_id_attr_group);
if (error)
printk(KERN_ERR
"serio: sysfs_create_group() failed for %s (%s), error: %d\n",
serio->phys, serio->name, error);
}
}
我们终于看到serio device注册的庐山真面目了。它会调用设备的start()函数,然后调用device_add()将设备注册到总线上。
同platform总线一样,这里的serio device注册的时候也会产生一个hotplug事件,对应就会调用总线的uenvent函数,在serio_bus的event接口为:
static int serio_uevent(struct device *dev, struct kobj_uevent_env *env)
{
struct serio *serio;
if (!dev)
return -ENODEV;
serio = to_serio_port(dev);
SERIO_ADD_UEVENT_VAR("SERIO_TYPE=%02x", serio->id.type);
SERIO_ADD_UEVENT_VAR("SERIO_PROTO=%02x", serio->id.proto);
SERIO_ADD_UEVENT_VAR("SERIO_ID=%02x", serio->id.id);
SERIO_ADD_UEVENT_VAR("SERIO_EXTRA=%02x", serio->id.extra);
SERIO_ADD_UEVENT_VAR("MODALIAS=serio:ty%02Xpr%02Xid%02Xex%02X",
serio->id.type, serio->id.proto, serio->id.id, serio->id.extra);
return 0;
}
可见。会在hotplug的环境变量中添加几项值。记得我们之前分析设备驱动模型的时候,在总线下面的设备都有一个属性文件,这个文件的内容就是对应bus和kset所添加的环境变量。在/sys文件系统中就可以看到这此环境变量。做个测试:
[root@localhost serio0]# cat /sys/bus/serio/devices/serio0/uevent
DRIVER=atkbd
PHYSDEVBUS=serio
PHYSDEVDRIVER=atkbd
SERIO_TYPE=06
SERIO_PROTO=00
SERIO_ID=00
SERIO_EXTRA=00
MODALIAS=serio:ty06pr00id00ex00
四:serio driver的注册
对应serio driver注册的接口噗serio_register_driver()。代码如下:
static inline int serio_register_driver(struct serio_driver *drv)
{
return __serio_register_driver(drv, THIS_MODULE, KBUILD_MODNAME);
}
它是__serio_register_driver()的封装函数,代码如下:
int __serio_register_driver(struct serio_driver *drv, struct module *owner, const char *mod_name)
{
int manual_bind = drv->manual_bind;
int error;
drv->driver.bus = &serio_bus;
drv->driver.owner = owner;
drv->driver.mod_name = mod_name;
/*
* Temporarily disable automatic binding because probing
* takes long time and we are better off doing it in kseriod
*/
drv->manual_bind = 1;
error = driver_register(&drv->driver);
if (error) {
printk(KERN_ERR
"serio: driver_register() failed for %s, error: %d\n",
drv->driver.name, error);
return error;
}
/*
* Restore original bind mode and let kseriod bind the
* driver to free ports
*/
if (!manual_bind) {
drv->manual_bind = 0;
error = serio_queue_event(drv, NULL, SERIO_ATTACH_DRIVER);
if (error) {
driver_unregister(&drv->driver);
return error;
}
}
return 0;
}
上面这段代码比较简单,在注册驱动的时候,将驱动的总线指定为serio_bus.然后调用driver_register()将驱动注册到总线。如果drv->manual_bind不为1。还会产生一个SERIO_ATTACH_DRIVER事件。 drv->manual_bind成员的含义应该是要手动进行驱动与设备的绑定。
在注册驱动的时候,会产生一次驱动与设备的匹配过程。这过程会调用bus->mach.busrobe.看下serio总线是怎么样处理的.
Serio_bus.match的函数如下:
static int serio_bus_match(struct device *dev, struct device_driver *drv)
{
struct serio *serio = to_serio_port(dev);
struct serio_driver *serio_drv = to_serio_driver(drv);
if (serio->manual_bind || serio_drv->manual_bind)
return 0;
return serio_match_port(serio_drv->id_table, serio);
}
如果驱动或者设备指定了手动绑定,那么这次绑定是不成功的。然后还会调用serio_match_port()进行更细致的判断。代码如下:
static int serio_match_port(const struct serio_device_id *ids, struct serio *serio)
{
while (ids->type || ids->proto) {
if ((ids->type == SERIO_ANY || ids->type == serio->id.type) &&
(ids->proto == SERIO_ANY || ids->proto == serio->id.proto) &&
(ids->extra == SERIO_ANY || ids->extra == serio->id.extra) &&
(ids->id == SERIO_ANY || ids->id == serio->id.id))
return 1;
ids++;
}
return 0;
}
由此看出,只有serio device信息与serio driver的id_table中的信息匹配的时候,才会将设备和驱动绑定起来。
Serio_bus.probe的接口函数如下示:
static int serio_driver_probe(struct device *dev)
{
struct serio *serio = to_serio_port(dev);
struct serio_driver *drv = to_serio_driver(dev->driver);
return serio_connect_driver(serio, drv);
}
static int serio_connect_driver(struct serio *serio, struct serio_driver *drv)
{
int retval;
mutex_lock(&serio->drv_mutex);
retval = drv->connect(serio, drv);
mutex_unlock(&serio->drv_mutex);
return retval;
}
即会调用设备驱动的connect()函数。
在注册serio driver的时候,还会产生SERIO_ATTACH_DRIVER事件。这个事件的处理是在serio_handle_event()中完成的。相应的处理接口为:
static void serio_attach_driver(struct serio_driver *drv)
{
int error;
error = driver_attach(&drv->driver);
if (error)
printk(KERN_WARNING
"serio: driver_attach() failed for %s with error %d\n",
drv->driver.name, error);
}
可以看出。这里也是执行一次设备与驱动的匹配过程。
Why! 为什么要这样做呢? 这次事件的动作实现上在driver_register()中已经做了。
五:serio 的中断处理函数分析
serio_interrupt()在serio bus构造的驱动也是一个常用的接口,这个接口用来处理serio 设备的中断。我们来看下它的代码:
irqreturn_t serio_interrupt(struct serio *serio,
unsigned char data, unsigned int dfl)
{
unsigned long flags;
irqreturn_t ret = IRQ_NONE;
spin_lock_irqsave(&serio->lock, flags);
if (likely(serio->drv)) {
ret = serio->drv->interrupt(serio, data, dfl);
} else if (!dfl && serio->registered) {
serio_rescan(serio);
ret = IRQ_HANDLED;
}
spin_unlock_irqrestore(&serio->lock, flags);
return ret;
}
首先,先判断当前设备是否已经关联到了驱动程序。如果已经被关联了,那么调用驱动的中断处理函数。如果没有。就会转入serio_rescan()中执行。该函数代码如下:
void serio_rescan(struct serio *serio)
{
serio_queue_event(serio, NULL, SERIO_RESCAN_PORT);
}
由此可见。它是执行了一个SERIO_RESCAN_PORT动作。同样,这个动作是在serio_handle_event()中处理的。相应的处理接口为:
static void serio_add_port(struct serio *serio)
{
int error;
if (serio->parent) {
serio_pause_rx(serio->parent);
serio->parent->child = serio;
serio_continue_rx(serio->parent);
}
list_add_tail(&serio->node, &serio_list);
if (serio->start)
serio->start(serio);
error = device_add(&serio->dev);
if (error)
printk(KERN_ERR
"serio: device_add() failed for %s (%s), error: %d\n",
serio->phys, serio->name, error);
else {
serio->registered = 1;
error = sysfs_create_group(&serio->dev.kobj, &serio_id_attr_group);
if (error)
printk(KERN_ERR
"serio: sysfs_create_group() failed for %s (%s), error: %d\n",
serio->phys, serio->name, error);
}
}
这样,相当于注册一个设备,注册时会产生设备与驱动的匹配事件。如果有合适的驱动,就会将之与设备关联起来。
六:小结
来小结一下,在serio总线中,总册一个serio设备时,除了将其注册到所属的serio_bus上。还会调用设备的start()函数。在中断处理的时候,如果serio 设备已经关联到驱动,则调用驱动的interrupt函数。如果没有关联,则将其注册到总线。
总的说来,erio 总线的代码很简单。到这里。我们已经分析过platform,serio两种虚拟总线,应该结合这两个虚拟总线的例子好好体会一下结构封装的技巧。
posted @
2010-08-07 11:55 lfc 阅读(2535) |
评论 (0) |
编辑 收藏Ubuntu的那个NetworkManager其实挺好的,只是前段时间常驻办公室,在那边只能用有线上网,还要修改MAC,手工指定IP,本来
在/etc/network/interfaces里面加上规则是很轻松的事情,可是NetworkManager让这件事情比在windows下还要麻
烦,于是一怒之下我就把他干掉了,而且还加了可爱的参数purge。
但是无线我就不会配了,回宿舍上网的两个解决方案是进windows和用有线。回家之后路由器扔在客厅,没法用有线了,咬咬牙,折腾了小半个下午,解决了无线的配置问题。
我的Wi-Fi信号是这样,802.11g,SSID广播,WPA2 Personal加密模式,WPA加密算法用TKIP,30位数字特殊符号大小写的密钥,客户端由DHCP分配IP。笔记本无线网卡是Inter 5100 AGN,操作系统是Ubuntu 9.10。
原理大概是这样,/etc/network/interfaces里面无线网卡配置的写法跟有线差不多,只是多需要了一个叫wpa_supplicant的程序,它的作用是对数据流进行加密,因此要在网卡up的时候启动它,在网卡down的时候关掉他。
具体的做法如下,首先iwconifg看一下无线网卡叫啥,我这块卡是能被系统认出来并驱动的,名字叫wlan0。
然后给wpa_supplicant写个配置文件,放在/etc/wpa_supplicant下面好了,管他叫wpa_supplicant.conf好了,如下。
ctrl_interface=/var/run/wpa_supplicant
ctrl_interface_group=root
network={
ssid=”……” #ssid的名字,如果ssid不是广播的话,在下面加一条scan_ssid=1。
key_mgmt=WPA-PSK
psk=”……” #引号里面明文写密钥
proto=RSN #据说WPA1是写WPA的,WPA2是写这个的。
pairwise=TKIP
}
明文写密钥比较变态,用wpa_passphrase ssid ‘psk’来生成一个加密的psk,效果如下。
# wpa_passphrase tplink ‘qwer!@#123′
network={
ssid=”tplink”
#psk=”qwer!@#123″
psk=8f7ccd4d208572d85eefadf6d80b66f27515a9de8f79743148cefb2c6785e0f5
}
根据输出重新替换回去就好。
接着在/etc/network/interfaces里面写
auto wlan0
iface wlan0 inet dhcp
wireless-ssid “……”
pre-up wpa_supplicant -B -Dwext -iwlan0 -c/etc/wpa_supplicant/wpa_supplicant.conf
post-down killall -q wpa_supplicant
pre-up就是在网卡up之执行一下wpa_supplicant -B -Dwext -iwlan0
-c/etc/wpa_supplicant/wpa_supplicant.conf,在后台启动一个wpa_supplicant的进程,这样
post-down的意思也就明了了。
然后就是/etc/init.d/networking
restart了,如果启动不成功的话,在确认没有低级错误的情况下,基本就是网卡的驱动问题了,man
wpa_supplicant了解更多,然后就是wpa_supplicant.conf里面的参数了,找找还有别的调整调整,调到满意为止。
主力参考了这篇 http://www.linuxhomenetworking.com/wiki/index.php/Quick_HOWTO_:_Ch13_:_Linux_Wireless_Networking,其他也google了一些,没有太多参考价值,参悟了wpa_supplicant的作用就明白了。
注:
本人觉得ubuntu的network manager那一套统一管理有线和无线设备的机制对用户来说更友好,有兴趣的话可以看看/etc/network/目录下的脚本文件,里面就是使用wireless-tools和wpa_supplicant工具管理无线网络的。
posted @
2010-05-20 20:45 lfc 阅读(6042) |
评论 (0) |
编辑 收藏Tslib解析
Author:Jiujin.hong
转载请说明出处:http://blog.csdn.net/hongjiujing or www.linuxforum.net嵌入式linux版块
tslib背景:
在采用触摸屏的移动终端中,触摸屏性能的调试是个重要问题之一,因为电磁噪声的缘故,触摸屏容易存在点击不准确、有抖动等问题。
Tslib是一个开源的程序,能够为触摸屏驱动获得的采样提供诸如滤波、去抖、校准等功能,通常作为触摸屏驱动的适配层,为上层的应用提供了一个统一的接口。
tslib插件:
pthres 为Tslib 提供的触摸屏灵敏度门槛插件;variance 为Tslib 提供的触摸屏滤波算法插件;dejitter 为Tslib 提供的触摸屏去噪算法插件;linear 为Tslib 提供的触摸屏坐标变换插
件。
触摸屏驱动为与硬件直接接触部分,为上层的Tslib 提供最原始的设备坐标数据,并可以配置采样间隔、屏幕灵敏度等。采样间隔决定了单位时间内的采样数量,在其他参数不变的
情况下,采样间隔越小意味着单位时间内的采样数量越多,也就意味着采样越逼真、越不容易出现采样信息丢失如输入法书写时丢笔划的情况,但因为噪声的影响,采样间隔越小同时
也意味着显示出来的图形的效果越差。
Tslib 为触摸屏驱动和应用层之间的适配层,其从驱动处获得原始的设备坐标数据,通过一系列的去噪、去抖、坐标变换等操作,来去除噪声并将原始的设备坐标转换为相应的屏幕
坐标。
tslib接口:
在tslib 中为应用层提供了2 个主要的接口ts_read()和ts_read_raw(),其中ts_read()为正常情况下的借口,ts_read_raw()为校准情况下的接口。
正常情况下,tslib 对驱动采样到的设备坐标进行处理的一般过程如下:
raw device --> variance --> dejitter --> linear --> application
module module module
校准情况下,tslib 对驱动采样到的数据进行处理的一般过程如下:
raw device--> Calibrate
由于各种相关期间的影响,在不同的硬件平台上,相关参数可能需要调整。以上参数的相互关系为:采样间隔越大,采样点越少,采样越失真,但因为信息量少,容易出现丢笔划
等丢失信息情况,但表现出来的图形效果将会越好;去噪算法跟采样间隔应密切互动,采样间隔越大,去噪约束应越小,反之采样间隔越小,去噪约束应越大。去抖算法为相对独立的
部分,去抖算法越复杂,带来的计算量将会变大,系统负载将会变重,但良好的去抖算法可以更好的去除抖动,在进行图形绘制时将会得到更好的效果;灵敏度和ts 门槛值为触摸屏的
灵敏指标,一般不需要进行变动,参考参考值即可。
过滤插件分析:
Variance:触摸屏滤波算法
问题:一些触摸屏取样非常粗略,因此,即使你持着笔不放,样本可能不同,有时会大幅增加。最坏的情况是由于采样的时候电噪声的干扰,可大大脱离现实笔的位置不同,这会导致鼠标光标移动“跳”起来,然后返回回来。
解决方法:延迟一个时隙采样数据。如果我们看到最后采样读出来的数据太多的不同,我们将其标示为“可疑”。如果下一个采样读取的数据接近“可疑” 情况出现之前的数据,“可疑”数据将被丢弃。否则我们认为笔正在进行一个快速的笔移动动作,“可疑”数据的采样和出现”可疑”数据之后的采样都将通过。
重要算法分析:
static int variance_read(struct tslib_module_info *info, struct ts_sample *samp, int nr)
{
struct tslib_variance *var = (struct tslib_variance *)info;
struct ts_sample cur;
int count = 0, dist;
while (count < nr) {
如果采样数据被标记为“提交噪音”状态,将当前采样数据相关结构体赋予噪音状态,将清除标志位。
if (var->flags & VAR_SUBMITNOISE) {
cur = var->noise;
var->flags &= ~VAR_SUBMITNOISE;
} else {
如果如果采样数据没有被标记为“提交噪音”,继续采样数据。
if (info->next->ops->read(info->next, &cur, 1) < 1)
return count;
}
如果当前没有压力值,处于没有笔触摸或者笔释放状态,但是却收到笔按下消息,表明为收到噪音干扰,
所有当笔一释放就立即清除队列,否则之前的层将捕抓到笔起来的消息,但是已经太晚,如果
info->next->ops->read()出现堵塞,将出现这种情况。
if (cur.pressure == 0) {
/* Flush the queue immediately when the pen is just
* released, otherwise the previous layer will
* get the pen up notification too late. This
* will happen if info->next->ops->read() blocks.
*/
if (var->flags & VAR_PENDOWN) {
var->flags |= VAR_SUBMITNOISE;
var->noise = cur;
}
/* Reset the state machine on pen up events. */
复位笔起来事件状态标记位
var->flags &= ~(VAR_PENDOWN | VAR_NOISEVALID | VAR_LASTVALID);
goto acceptsample;通知接受采样数据
} else
var->flags |= VAR_PENDOWN;通知笔按下
如果标记位与“VAR_LASTVALID"状态不同,进行下一个采样。
if (!(var->flags & VAR_LASTVALID)) {
var->last = cur;
var->flags |= VAR_LASTVALID;
continue;
}
如果为笔按下事件
if (var->flags & VAR_PEN DOWN) {
/* Compute the distance between last sample and current */
计算上一次的采样数据与当前采样数据的距离
dist = sqr (cur.x - var->last.x) +
sqr (cur.y - var->last.y);
if (dist > var->delta) {如果误差大于默认值,比如30。
视之前的采样为噪音?可疑?
/* Do we suspect the previous sample was a noise? */
if (var->flags & VAR_NOISEVALID) {
但是如果之前的采样已经是可疑状态,视为快速的笔移动触发动作。
/* Two "noises": it's just a quick pen movement */
samp [count++] = var->last = var->noise;
var->flags = (var->flags & ~VAR_NOISEVALID) |
VAR_SUBMITNOISE;
} else
如果之前的采样并不是可疑状态,视为可疑状态.
var->flags |= VAR_NOISEVALID;
/* The pen jumped too far, maybe it's a noise ... */
var->noise = cur;
continue;
} else
var->flags &= ~VAR_NOISEVALID;采样的数据属于正常数据.
}
acceptsample:
#ifdef DEBUG
fprintf(stderr,"VARIANCE----------------> %d %d %d\n",
var->last.x, var->last.y, var->last.pressure);
#endif
samp [count++] = var->last;
var->last = cur;
}
return count;
}
dejitter 去噪插件分析:
问题:一些触摸屏从ADC获取X/Y坐标采样值,他们的最低位带有很大的噪音干扰,这就导致了触摸屏输出值的抖动。
比如我们保持着按某一点,我们会得到许多的X/Y坐标采样,他们相近但是不相等。同时如果我们试图在一个画图程序里面去画一个直线,
我们将得到一个充满“毛刺“的直线。
解决:我们对最后几个值应用一个重量平滑滤波,从而去除输出“毛刺”。我们发现坐标发生重大变化,我们会重新设置笔位置的积压,从而
避免平滑不应该要平滑的坐标。当然,这些都是假设所有噪音都已经由底端过滤器滤波过了,例如variance模块。
工作原理:
该过滤器的工作原理如下:我们掌握最新的N样本轨道,我们不断跟踪最新的N个采样,根据一定的重量求平均。最旧的数据有最少的重量,最近的数据
有最大的重量。这有助于消除抖动,同时不影响响应时间,因为我们为每一个输入采样输出一个输出样本,笔移动会变得更加顺畅。
重要算法分析:
为了让事情简单(避免误差),我们确保SUM(重量)=2次方。同时当我们有不到默认采样数量的时候,我们必须知道怎么去近似测试。
static const unsigned char weight [NR_SAMPHISTLEN - 1][NR_SAMPHISTLEN + 1] =
{
/* The last element is pow2(SUM(0..3)) */
{ 5, 3, 0, 0, 3 }, /* When we have 2 samples ... */
{ 8, 5, 3, 0, 4 }, /* When we have 3 samples ... */
{ 6, 4, 3, 3, 4 }, /* When we have 4 samples ... */
};
static void average (struct tslib_dejitter *djt, struct ts_sample *samp)
{
const unsigned char *w;
int sn = djt->head;
int i, x = 0, y = 0;
unsigned int p = 0;
w = weight [djt->nr - 2];找出与重量数组相对应的数据,例如如果是第一次采样就没有,如果是第二次采样,就对应{ 5, 3, 0, 0, 3 },依此类推。
for (i = 0; i < djt->nr; i++) {
x += djt->hist [sn].x * w [i];
y += djt->hist [sn].y * w [i];
p += djt->hist [sn].p * w [i];
sn = (sn - 1) & (NR_SAMPHISTLEN - 1);记录每一次采样的序号
}
samp->x = x >> w [NR_SAMPHISTLEN];求出平均值
samp->y = y >> w [NR_SAMPHISTLEN];
samp->pressure = p >> w [NR_SAMPHISTLEN];
#ifdef DEBUG
fprintf(stderr,"DEJITTER----------------> %d %d %d\n",
samp->x, samp->y, samp->pressure);
#endif
}
static int dejitter_read(struct tslib_module_info *info, struct ts_sample *samp, int nr)
{
struct tslib_dejitter *djt = (struct tslib_dejitter *)info;
struct ts_sample *s;
int count = 0, ret;
ret = info->next->ops->read(info->next, samp, nr);
for (s = samp; ret > 0; s++, ret--) {
if (s->pressure == 0) {
/*
* Pen was released. Reset the state and 如果笔释放,复位状态标准,同时丢弃所有历史事件。
* forget all history events.
*/
djt->nr = 0;
samp [count++] = *s;
continue;
}
/* If the pen moves too fast, reset the backlog. */ 如果笔移动太快,复位积压
if (djt->nr) {
int prev = (djt->head - 1) & (NR_SAMPHISTLEN - 1);
if (sqr (s->x - djt->hist [prev].x) +
sqr (s->y - djt->hist [prev].y) > djt->delta) { 如果之前的x的平方距离值与之前的y的平方距离值加入门槛值,提示超过门槛值,丢弃,复位。
#ifdef DEBUG
fprintf (stderr, "DEJITTER: pen movement exceeds threshold\n");
#endif
djt->nr = 0;
}
}
djt->hist[djt->head].x = s->x;
djt->hist[djt->head].y = s->y;
djt->hist[djt->head].p = s->pressure;
if (djt->nr < NR_SAMPHISTLEN) 如果采样数小于默认采样数,继续执行
djt->nr++;
/* We'll pass through the very first sample since
* we can't average it (no history yet).
*/
if (djt->nr == 1) 如果这是第一次采样,没有历史或者旧采样数据,直接赋值。
samp [count] = *s;
else { 如果不是第一次采样,就执行平均函数,求得经过平均后的采样值。
average (djt, samp + count);
samp [count].tv = s->tv;
}
count++;
djt->head = (djt->head + 1) & (NR_SAMPHISTLEN - 1);记录采样的序号
}
return count;
}
总结:经过分析varience滤波模块插件和dejitter去抖模块插件,我们知道如下:
1:varience是最低层滤波插件,方差滤波器,试图做得最好,过滤掉由ADC采样过来的随机噪音,通过限制某些采样的运动速度,例如:
笔不应该比一些门槛值快一些。
主要参数:门槛值delta
求出之前的采样点和当前的采样点的平方距离(X2-X1)^2 + (Y2-Y1)^2),用来确定两个样本是“近”还是“远”。如果以前和目前的样本之间的距离是'远',
样品被标记为'潜在噪音'或者“可疑“,但这并不意味着它将被丢弃。如果下次的采样接近于它,我们将视是一次普通的快速移动动作。同时如果“潜在噪音"之后的采样比之前讨论的
采样都“远”,也将认为出现了一次普通的快速移动动作。如果出现“潜在噪音”之后的采样和出现“潜在噪音“之前的采样相近,我们将丢弃”潜在噪音 “这次数据,认为它为要过滤的噪音。
2:dejitter去抖模块插件
去除X/Y坐标的抖动,这是通过使用一个加权平滑滤波器实现的。最近的采样有最重的重量,早期的采样有重量轻的重量,这使得实现1:1的输入-输出速率。
主要参数:门槛值delta
两个采样之间的平方距离,(X2-X1)^2 + (Y2-Y1)^2),即定义了'快速运动'的门槛。如果笔移动快,平滑笔的动作是不合适的,另外,快速运动任何时候都不是准确的。所以如果检测到了快速运动,
该过滤模块只是简单地丢弃积压和复制输入到输出。
另外有兄弟比较懂dejitter这个插件的,可以详细讲一下,先谢谢了!
Changelog:
1:Post initial version
posted @
2010-05-06 11:28 lfc 阅读(2954) |
评论 (0) |
编辑 收藏