1、前言
这里接着前面的
linux内存管理----paging_init,再仔细的深挖一下内核页表的建立,特别基于arm32的处理。
2、内核页表的建立
首先,内核页表的基地址已经在此前确定了,为物理起始地址的 0x00004000 偏移处,占用 16K 的连续物理内存,将新建立的页表保存在该物理地址上即可,毕竟 MMU 要求内核给出的页表基地址为物理地址。
实际上,起始地址偏移
0x00004000~0x00008000 这一段物理地址映射的是 4G 的内存,而内核只占用了最高 1G 内存,因此内核实际页表项的地址为
起始物理地址+0x00007000,不过设置到 MMU 的地址依旧是 0x00004000 偏移处。
同时,内核中只有线性映射区才会直接建立页表,而对于高端内存是无法建立页表的,这并不难理解,假设物理内存有 1.5 G,已经超出了内核本身的线性空间,自然有一部分物理内存是无法建立直接映射的,关于内核中的内存区域 ZONE 的概念可以参考 buddy 框架的建立。
有个不太好理解,但是非常重要的概念是:内核中线性映射区对于物理内存的映射仅仅是建立映射,仅仅是为了内核可以直接访问这些内存,从而进行管理,而用户空间使用内存时建立的内存映射是基于内存分配的需求。
因此,对于用户空间而言,虚拟内存到物理内存的映射必须是分配大小的粒度,也就是
4K,但是内核中可以使用 section map,也就是 1M 的映射,这并不影响内核对物理内存的管理,管理和分配时照样可以使用 4K
的粒度进行,毕竟 pfn 和 struct page 都是以 4K 页面进行索引的。
内核中使用 section 映射的好处在于:
- 节省内存,不再需要分配二级页表项 block(一个 blcok 包含 256 项二级页表项)
- 节省内存访问时间,内存访问只需要翻译一次,不需要经过二级页表项的翻译
pgd、pud、pmd、pte
对于 arm32
而言,硬件上就决定了可以使用一级页表(section map)或者二级页表(page table map),对于 64
位系统而言,因为支持的线性内存空间巨大,需要使用 4 级页表,linux 为了兼容所有的硬件设备,因此内核统一支持 4 级页表(或者 5
级,还有一级 p4d 介于 pgd 和 pud 之间,基于同样的原理进行扩展的中间页表项):
- pgd:页全局目录
- pud:页上级目录
- pmd:页中间目录
- pte:页表项入口
对于不同级别的页目录(entry),对应内核中不同的数据类型:
typedef u32 pmdval_t;
typedef pteval_t pte_t;
typedef pmdval_t pmd_t;
typedef pmdval_t pgd_t[2];
typedef pteval_t pgprot_t;
对于 arm32 而言,并不需要使用到 pud 和 pmd,直接让 pgd 目录项指向 pte 即可,将 pud 和 pmd 折叠,做法就是直接让 pud 和 pmd 指向 pgd,这种折叠并没有太多成本,只是在创建页表的时候多两层函数调用而已。
大体上对应的结构为(粗略图):
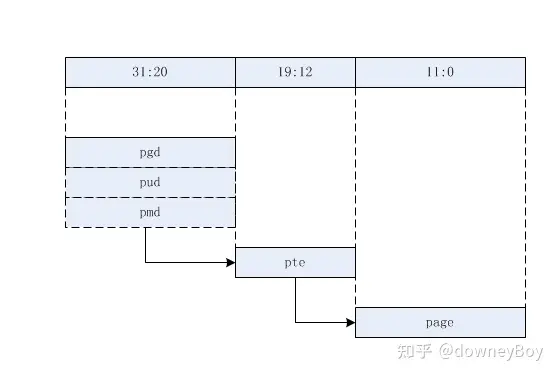
硬件页表与内核页表
在 arm页表硬件实现
中介绍到,armv7 规定在实现 4K page table map 时,二级页表项为 256 项,每项占用 4 bytes,一个二级页表
block 占用 1K 的空间,但是问题在于页面大小为 4K,因此需要多个二级页表 block 存放到一个 page
中,以免造成内存的浪费。理论上一个 page 中可以存放 4 个二级页表 block。
实际情况并不是这样,由于
armv7 处理器设计的特殊性,对于存放二级页表 block 的页面,每个页面只会存放两个二级页表 block,这是硬件页表
block,剩下的 2K 空间存放的是对应的内核页表 block,也就是对同一片内存区域的映射而言,需要建立两个页表映射,为什么 arm
内核针对同一个内存映射区域会需要两个页表block?
在 x86 架构 MMU 的 page table entry 中,有三个标志位是硬件规定的:
- PTE_DIRTY:页面 dirty 位,CPU 对页面执行写操作时会将该页面的 dirty 位置位,说明页面被修改,是脏页。
- PTE_YOUNG:MMU 寻址时会对页面的该标志位置位,该标志位被置位的的页面说明在不久前被使用过,因此在页面换出的时候不会考虑该页
- PTE_PRESENT:用于判断页面是否在内存中。
由于 linux 最早是在 x86 平台上运行的,因此内存管理也就继承自 x86 的架构。但是在 armv7 对于页表的规定中,二级页表项中并不包含这些重要的标志位,因此,硬件的缺失需要通过软件来实现。
解决方案是:对应所有的二级页表 block,提供两份,一份给硬件用于 MMU 地址翻译,而另一份给 linux 内核,用于软件模拟上述标志位,其硬件规定的二级页表项为:

高 20 bits 用于物理寻址,低 12 bits 则是内存标志位,对于 linux 软件页表而言,高 20 bits 相同,而低 12
bits 用于 pte_dirty、pte_young 等标志位,这些标志位被定义在
arch/arm/include/asm/pgtable-2level.h 中:
#define L_PTE_VALID (_AT(pteval_t, 1) << 0) /* Valid */
#define L_PTE_PRESENT (_AT(pteval_t, 1) << 0)
#define L_PTE_YOUNG (_AT(pteval_t, 1) << 1)
#define L_PTE_DIRTY (_AT(pteval_t, 1) << 6)
#define L_PTE_RDONLY (_AT(pteval_t, 1) << 7)
#define L_PTE_USER (_AT(pteval_t, 1) << 8)
#define L_PTE_XN (_AT(pteval_t, 1) << 9)
#define L_PTE_SHARED (_AT(pteval_t, 1) << 10)
#define L_PTE_NONE (_AT(pteval_t, 1) << 11)
那么,软件上是如何模拟这些 x86 中的硬件标志位的呢?
- PTE_DIRTY:对于新分配的页面,先将其映射为只读,当对该页面执行写操作时,会触发 MMU fault,在异常处理程序中将标志位进行修改
- PTE_YOUNG:在页面分配的时候被置位,解除映射的时候清除
- PTE_PRESENT:其实一个虚拟页面有没有在内存中有两种情况,一种是页面压根就没被分配,另一种是被换出了,如果页面是被换出的,那么 PTE_YOUNG 会被置位,而 PTE_PRESENT 会被清除,如果是压根没有分配,两个标志位都为 0。
对于一个装有二级页表 block 的 page,它的布局为:
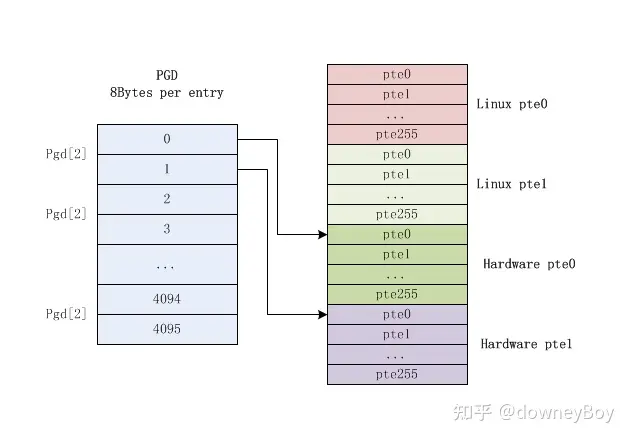
左边是一级页表项 block,而右边是一个 page 中包含的四个(两对)二级页表 block 项,硬件页表项放在软件页表项 +2048 处。
linux 页表软件上的处理
从上面的分析不难看出,linux 软件实现的页表和 arm 中硬件定义的页表是有差别的,严格来说 linux 软件在硬件页表的基础上进行了一些调整,主要为以下几点:
1: linux 内核为了兼容各种体系架构,使用了 4(5) 级页表,当然 arm 实际上使用了其中两级。
2:armv7 MMU 硬件上不支持 dirty、young 等标志位,但是内核内存管理框架需要应用这些标志,因此在软件上对每一个页表项需要额外增加模拟二级页表项
3:
鉴于 arm 硬件定义的二级页表 block 为 256 项,每项 4 bytes,占用 1K,加上软件模拟页表项为
2K,但是一个最小的页面为 4K,因此需要将 4 个二级页表 block(2个linux 软件模拟 pte block + 2个硬件 pte
block) 放到一个页面中,每个 PGD 项实际上是占用 8 bytes,因此有以下定义:
#define PMD_SHIFT 21
#define PGDIR_SHIFT 21
#define PMD_SIZE (1UL << PMD_SHIFT)
#define PMD_MASK (~(PMD_SIZE-1))
#define PGDIR_SIZE (1UL << PGDIR_SHIFT)
#define PGDIR_MASK (~(PGDIR_SIZE-1))
PMD_SIZE 被定义为一个 PMD 能够映射的内存大小,PMD_SIZE = 1 << 21 = 2M。
从硬件定义来看,每个
pte block 应该是 1M,SHIFT 值应该是 20,但是软件上的处理为:将两个 pte block 放在一个页面中,因此每个 PGD
占用 8 bytes,而 PMD = PGD,因此 PMD 也就相当于两个 pte block,两个页面也就是 2M,SHIFT 为 21。
注:以上介绍可以参考linux内核下arch/arm/include/asm/pgtable-2level.h的注释建立映射
内核线性映射内存区映射的建立在 paging_init ->
map_lowmem 函数中,对于所有的空闲内存,默认映射为 RW 属性,而对于内核而言,需要加上 X
属性,不然内核代码无法执行,尽管内核在开启 MMU
的阶段已经映射过了,但是那毕竟只是在不知道物理内存信息的情况下建立的临时映射,因此内核需要重新映射为 RWX 属性,而 dtb 占用的内存也是
RW 属性,和空闲内存一起做映射即可。
因此,内核线性空间的映射通常被分为三个部分:
- 内核镜像之前的物理内存映射,RW 属性
- 内核镜像的重新映射,RWX 属性
- 内核镜像之后的物理内存映射,RW 属性
在 map_lowmem 函数中,先是对上面所提到的三个内存区域空间进行计算,然后分别映射,建立内存映射的函数为 create_mapping,该函数接受一个 struct map_desc 类型的参数:
struct map_desc {
unsigned long virtual;
unsigned long pfn;
unsigned long length;
unsigned int type;
};
这个参数非常好理解,既然是虚拟内存到物理页面的映射,自然包括虚拟内存地址、物理页面页帧号 pfn,映射长度以及映射类型。
create_mapping 函数实现为:
static void __init create_mapping(struct map_desc *md)
{

__create_mapping(&init_mm, md, early_alloc, false);
}
create_mapping 函数就是对 __create_mapping 函数的封装,__create_mapping 的几个参数得聊一聊:
- init_mm:尽管内核初始化早期调度子系统没有就绪,但是内核静态定义了一个
init 进程,内核初始化流程就是运行在该进程中,对于任何进程都会有其对应的一份页表来描述虚拟地址到物理地址的映射,这个页表只是 pgd
block(一级页表 block),保存所有的 pgd,而所有的 pte block 是按需动态分配的。 因此,task struct
结构中保存了页表基地址,具体成员为 task->mm->pgd,对于 init 进程而言,其 struct_mm
结构也是静态定义的,因此 __create_mapping 第一个参数需要提供进程的 mm 结构,实际上主要是提供当前进程的 pgd 首地址。
- md: struct map_desc ,包括建立映射需要的几个关键参数,见上文。
- early_alloc:内存分配接口,如果是
page table 映射,使用二级页表,那么对应的二级 pte block 就需要动态分配内存,early_alloc 底层调用的还是
memblock 的内存分配接口,毕竟这时候 buddy 子系统还没有初始化完成。
- ng:
__create_mapping 传入的第四个参数为 false,这个参数实际对应 ng 标志位,这个标志位的作用在 armv7
手册中被定义的(也就是硬件决定的),为 not global bit,如果该标志为 false,表示页表是对所有 processor
可见的,如果为 true,表示页表只对特定的 processor 可见。
在 __create_mapping 中,通过 __pfn_to_phys 宏获取映射的物理地址,这个宏就是将 pfn 左移 PAGE_SHIFT bits。
接着,需要将传入的映射长度向页面对齐,再通过 pgd_offset 宏获取目标内存 pgd 的地址,这个宏首先会通过进程的 mm->pgd 获取一级页表 block 的基地址,然后通过虚拟地址的偏移获取对应的页表项。
因为是建立映射,除了
pgd 已经被创建之外,需要创建对应的 pud、pmd 和 pte 项,于是接着调用 alloc_init_pud 和
alloc_init_pmd,二级映射中不使用 pud 和 pmd,因此直接将 pud 和 pmd 指向 pgd,在
alloc_init_pmd 函数中,根据传入的参数选择映射的方式:
static void __init alloc_init_pmd(pud_t *pud, unsigned long addr,
unsigned long end, phys_addr_t phys,
const struct mem_type *type,
void *(*alloc)(unsigned long sz), bool ng)
{
pmd_t *pmd = pmd_offset(pud, addr);
unsigned long next;
do {
if (type->prot_sect &&
((addr | next | phys) & ~SECTION_MASK) == 0) {
__map_init_section(pmd, addr, next, phys, type, ng);
} else {
alloc_init_pte(pmd, addr, next,
__phys_to_pfn(phys), type, alloc, ng);
}
}
在执行 __create_mapping
时,如果需要映射的长度大于 2M(针对 arm,每个平台不同),就将需要建立映射的内存以 2M 为分割进行处理,这是因为 2M
的映射刚好对应两个二级页表 block,填充一个完整的页面,方便处理。从上面的代码可以看出,如果需要建立的映射长度大于 1M 就会调用
__map_init_section 建立 section 映射。否则就调用 alloc_init_pte 建立 4K 映射。
__map_init_section
建立 1M 的 section 映射还是比较简单的,只需要生成对应的一级页表项,前 12 bits 对应虚拟地址到物理地址的映射,后 20
bits 对应一些属性位,在用户访问使用该映射时,该一级页表项的 前12bits + 输入的虚拟地址的后 20bits
就可以找到对应的物理内存地址。
建立 4K 的映射相对要麻烦一点,因为 4K 的页面映射需要使用二级页表,如果对应页面的二级页表 block 还没有被创建,首先需要调用 alloc 申请对应物理内存来保存二级页表 block,创建完成之后需要填充对应的一级页表项。
然后就可以直接使用 pte_offset_kernel 宏获取当前页面在二级页表 block 中对应的二级页表项地址,从而在该位置上填充对应的二级页表项数据,对于 4K 的映射,一级页表项和二级页表项内容在arm页表硬件实现中已经详细讨论过。
建立二级页表项由
set_pte_ext 宏实现,实际上底层调用的是在内核启动之初获取的
list->processor->set_pte_ext,这是处理器相关的处理函数,对应的函数实现为
cpu_v7_set_pte_ext,在 arch/arm/mm/proc-v7-2level.S 中。
ENTRY(cpu_v7_set_pte_ext)
#ifdef CONFIG_MMU
str r1, [r0] // 将 r1 保存到 r0 位置,也就是把 entry 值写入对应位置
// 这是 linux pte
tst r1, #L_PTE_YOUNG
tstne r1, #L_PTE_VALID // r1 = 0x3fffe18f
eorne r1, r1, #L_PTE_NONE // r1 = 0x3fffe98f
tstne r1, #L_PTE_NONE // r1 = 0x3fffe98f
moveq r3, #0 // r3 = 0x3fffe23e
ARM( str r3, [r0, #2048]! ) // 把 r3 存到 0xefffdfc0(r0+2048),这是硬件 pte
ALT_SMP(W(nop))
ALT_UP (mcr p15, 0, r0, c7, c10, 1) @ flush_pte
#endif
bx lr
ENDPROC(cpu_v7_set_pte_ext) set_pte_ext 接受三个参数:
1、pte ,也就是 entry 需要存放的地址
2、pte value,也就是 pte 对应的值
3、ng flag,和缓存策略相关的参数。
在
set_pte_ext 中,除了设置地址映射部分之外,还需要处理大量标志位的设置(比如 YOUNG、DIRTY
bit),毕竟针对同一个页面,需要填充一个软件二级页表项和一个硬件二级页表项,硬件二级页表项给 MMU 使用,保存在 软件二级页表项 +
2048 地址处,在上面贴出的汇编代码中也有体现,而完整的汇编处理就没有贴出来了,有兴趣的可以自己去研究研究。
注:转自linux内存子系统 - 建立内核页表
posted on 2022-12-29 16:20
lfc 阅读(366)
评论(0) 编辑 收藏 引用