|
|
http://www.pcpop.com/doc/0/150/150436.shtml
http://www.pconline.com.cn/diy/graphics/study_gra/0612/929976.html
http://linghuye.googlepages.com/GLView_XMLs.7z
Radeon 7000的性能相当于GeForce 256 SDRAM,Radeon 7200介于GeForce256 DDR与GeForce2 GTS之间,Radeon 7200LE约等于GeForce2 MX400,而Radeon7500则完全和GeForce2 Ti打成平手,并且完全超越GeForce2 GTS. DirectX7终极产品:Radeon 7500,Radeon 8500能够提供完整的DirectX 8.1 API硬件级支持,Radeon 9700/Pro实现DirectX 9.   
最近将我的DestinyMatrix图形接口用DirectX实现了一遍,过程中接口又进化了一次,现在可以像WoW一样选择使用那个API来渲染WoW的场景,觉得挺不错的.又用HLSL实现了一次骨骼动画:  struct VS_INPUT struct VS_INPUT
   { {
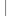 float3 position : POSITION; float3 position : POSITION;
float2 texCoord : TEXCOORD0;
float4 weight : BLENDWEIGHT;
float4 bone : BLENDINDICES;
 }; };
struct VS_OUTPUT
{
float4 position : POSITION;
float2 texCoord : TEXCOORD0;
float4 color : COLOR;
};
uniform matrix modelViewProj;
uniform matrix boneMatrices[60];
void main(in VS_INPUT inVert, out VS_OUTPUT outVert)
{
float4 blendVertex = float4(0.0f, 0.0f, 0.0f, 0.0f);
float4 blendWeight = inVert.weight;
int4 blendBone = int4(inVert.bone);
for(int i = 0; i < 4; i++)
  { {
if(blendWeight.x > 0.0f)
{
blendVertex += mul(float4(inVert.position, 1.0f), boneMatrices[blendBone.x]) * blendWeight.x;
blendBone = blendBone.yzwx;
blendWeight = blendWeight.yzwx;
 } }
}
outVert.position = mul(blendVertex, modelViewProj);
outVert.texCoord = inVert.texCoord;
outVert.color = float4(1.0, 1.0f, 1.0f, 1.0f);
}对比HLSL和GLSL, 1.OpenGL里的顶点属性attribute在DirectX里是通过SetStreamSource设置进去,感觉OpenGL的顶点attribute的思想更灵活. 2.为了实现接口,DirectX使用了多流模式与OpenGL的glXXXPointer保持思想上的兼容. 3.GLSL和Cg的顶点计算是标准数学的mul(mat, v),而HLSL是mul(v, mat),我调试了很久才发现 :( 4.HLSL的modelViewProj需要外部程序使用LPD3DXCONSTANTTABLE设置Matrix变量,而GLSL是内置的变量不需要外部传入.
平生酷爱科幻电影,看片无数,最爱<The Thirteenth floor>,其次<黑客帝国>,再次<人工智能>.
看<The Thirteenth floor>时大三,星期六,校台播的,第二天英语4/6级考试,而我已考过,其他人都上自习去了,宿舍只剩我在看.
我当时抱着<Windows高级编程指南>看完这片子,当看到主人公走到那个绿色三角网格的世界尽头时,心想这分明就是那个4G虚拟内存空间的边界,看完后就觉得自己天生就应该做程序员.<The Thirteenth floor>讲的其实就是矩阵中的矩阵,片尾如电视关机的效果也也预示这无尽嵌套的矩阵.
<黑客帝国>讲的是一个程序系统升级的过程,很有哲理,我觉得对写游戏系统的程序员很有启发意义.
矩阵系统规定了世界的物理定律,每个对象的感受.
可以想象矩阵系统中的每个程序对象都继承于CAIObject,能力有高有低,懂得保护自己对象实例的生存,懂得躲避系统的delete操作.成功逃离系统的对象好比是野指针,系统是删不掉他们的,乱删可能导致整个系统的崩溃.为了平衡,必须容忍他们的存在.
接入系统的人类应该没有继承于CAIObject,而是继承于一个更低级的CObject,以表现在矩阵系统中.NEO是个特别的对象,CNeo当然也继承于CObject,也可能继承于CAIObject,同时他还是个人类,多重继承.由于他随带的代码功能很强,可能CNeo是CMatrix的友员类,甚至可以调用矩阵系统的private函数,修改CMatrix的内部运作.
Neo这个实例对象能在现实世界操控机器章鱼一点不奇怪,他脑子里就附带着芯片代码什么的,可以和矩阵系统进行无线联网,控制机器的运作.
研究矩阵系统的进化很有意思,程序员讲方程式平衡,老巫婆讲模糊选择,但是她自己也不清楚结局会怎样,最后她运气好,矩阵进化了.如同庞大的程序系统,写到最后程序员也无力控制其发展,难以想象其运行的最终形态.
<人工智能>对AI的人类感情上描绘得很深刻,<撕裂的末日>片子中贝多芬交响曲想起时十分震撼,<迷失太空>那个塌陷的黑洞很好看,<香草的天空>,<人猿星球>,<少数派报告>,<变人>,<终结者>,<移魂都市>每个片子都能给人以思想上的娱悦.
1.有客户端开多线程对服务器进行连接断开压力测试,在连接接近4000次时,再也连接不上服务器,过了段时间后恢复正常,而后再出现,如此往复.使用Prcess Explorer查看System Idle Process发现大量的TIME_WAIT状态下的Socket. 解析如下:TCP TIME-WAIT 延迟断开TCP 连接时,套接字对被置于一种称为TIME-WAIT 的状态。这样,新的连接不会使用相同的协议、源 IP 地址、目标 IP 地址、源端口和目标端口,直到经过足够长的时间后,确保任何可能被错误路由或延迟的段没有被异常传送。在RFC 793 中,将这种套接字对不被其它连接重新使用的时间长度指定为 2 个MSL(最大段生存时间的 2 倍)或 4 分钟。对于Windows NT 和Windows 2000 来说,这是默认设置。然而,在此默认设置下,某些网络应用程序在很短时间内执行多个出站连接,就可能会在端口收回前用完所有的可用端口。Windows NT 和Windows 2000 提供两种方法来控制这种情况。第一种方法是使用TcpTimedWaitDelay 注册表参数,改变该数值。对于 Windows NT 和Windows 2000,其值最低可设置为30 秒,这样在大多数情况下不会出现问题。每二种方法是使用 MaxUserPorts 注册表参数,来配置用户可访问的临时端口数(用作出站连 接的源端口)。默认情况下,当应用程序从系统请求任何套接字用于出站调用时,就会提供一个数值在1024 到 5000 之间的端口。MaxUserPorts 参数可用于设置管理员所允许的出站连接的最大端口值。例如,将该值设置为10,000(十进制),就会有约 9000 个用户端口可用于出站连接。关于这一概念的详细信息,请参见 RFC 793,也可参见MaxFreeTcbs 和 MaxHashTableSize 注册表参数。 注册表位置: HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters主动断开的一方进入TIME_WAIT状态,被动断开的一方进入CLOSE_WAIT状态.不要试图使用SO_DONTLINGER设置避免TIME_WAIT状态!!!
On a busy HTTP server, the number of sockets in this TIME_WAIT state can far exceed those in the ESTABLISHED state. For instance, I checked an IIS 6.0 box that serves a fairly busy corporate site earlier today and got 124 ESTABLISHED connections versus 431 in TIME_WAIT.
The side shutting down the connection gets the TIME_WAIT. It's typical for a webserver to shutdown the connection immediately after sending a response. If you can instead stash the connection away and give the client time to close it you can push the TIME_WAIT to them. I believe Apache does something like this. In the worst case, if the client doesn't shutdown the connection, say within 5 seconds, you'll have to do it and suffer the TIME_WAIT. However if in that time the client does initiate the close then you have avoided a TIME_WAIT. 2. If you are using I/O completion ports, note that the order of calls made to WSASend/WSARecv is also the order in which the buffers are populated. WSASend//WSARecv should not be called on the same socket simultaneously from different threads, since it can result in an unpredictable buffer order. 3.作客户端开1024个稳定连接到服务器,然后使用Prcess Explorer强行非法关闭该客户端,1024个连接瞬间被异常断开,服务器将不能检测到所有socket的断开,如果是完成端口,即时当前打开KeepAlive,即时当前正在执行异步 WSARecv, GetQueuedCompletionStatus仍然可能无法返回正确的错误提示客户端关闭! Socket资源将残留.原来我以为仅在瞬间断电,操作系统崩溃,网线拔开这3种情况下才会发生该现象,看来进程崩溃也可以导致,只是以前的socket数量不足以让操作系统来不及处理. References:
Windows 2000 TCP/IP 实现详述
http://www.port80software.com/200ok/archive/2004/12/07/205.aspxhttp://support.microsoft.com/kb/q196271/
今天在看<3D Game Engine Design>时,突然发现LRN好像是专门做游戏编程电子书的组织,于是到emule上搜索LRN,搜到一批没见过的游戏编程相关书籍,于是狂下载之.
最近还发现街上那些做数码图文的,能打印电子书并装订成书籍,每页3毛钱,花RMB180能做一本跟原版差不多的600页的$70的游戏编程书籍,把我高兴坏了,对着Amazon上的书可以少流点口水了,
上帝保佑那些无私地为程序员做e书的人们.
中国邮政是垃圾!
China post is garbage!
把我的信用卡寄没了,银行给了挂号信编号,邮政还不让查,言制度如此,打个太极推给对方寄送邮局.其工作人员翻白眼球的本领堪称一绝,好个:孤月浪中翻.
幸亏银行运作是商业化了,服务热线小姐的态度很好,答应前卡作废,再寄一张过来.
网上搜了邮政的一则趣闻:
有人去邮局寄一件衬衣,一称重量为230克,可按照邮局的《邮政资费表》的有关规定,500克以上方能按包裹收寄。而500克以下只能寄特快件,邮资要20多元。可这件衬衣才值12元。于是邮寄人想出个法子,给包裹里放块砖头。于是,重量过了500克,可以按包裹寄了,才花3元。包裹单上“邮寄物品”一栏里,赫然地填着“衬衣和砖头”。
今天想通一个问题,如何异步地加载3D资源,进而实现整个地图块的后台异步加载机制,进而实现无缝大地图加载. 3D资源(纹理,顶点缓冲等)的加载分两个阶段,首先是数据加载,而后是根据读入的内存进行3D资源构造. 发现,IO操作的耗时远比3D资源构造多得多,3D资源构造,如glTexImage,glBufferData,Lock,Unlock速度相对还是很快的,而如果把整个加载放入一个线程导致跨线程3D资源的构造和使用上的问题. 理论上在一个线程创建的3D资源不能在另一个线程内使用(如OpenGL),即使可以做到(如DirectX的CREATE_MULTITHREADED),也会出现很多需要同步的3D资源句柄. 所以将纯IO操作加载阶段放入一个线程,将分析内存进行3D资源构造的阶段放到主线程的空闲时间处,能最简单地实现异步加载方案. 进而,在该逻辑运行下,出现这样的结果:所有的节点对象被建立出来,所有的3D资源类对象被建立出来,但类对象里的3D资源是空的,所以上层的逻辑仍在流畅地运行,但作图都是空的. IO线程,从数据读取请求队列取出请求,进行IO操作,将请求放入完成队列. 主线程在渲染完成后,判断IO完成对列中是否有完成的请求,计算当前空闲时间是多少,如要保持流畅25帧,每帧40毫秒,当前花了25毫秒,还有15毫秒可以消费且可以保持流畅. 在15毫秒内处理完成队列里的每个请求,使用请求里的内存进行3D资源构造,如glTexImage,Lock,Unlock直到超过15毫秒或队列被处理完.即最小可控制粒度为当前这个资源的构造时间.假设有一张很大的纹理的显卡构造花了20毫秒(一般不可能),超出15毫秒,那游戏就会出现稍微的卡. 系统内每个对象都可能处在一种Shell状态,光有抽象逻辑上的意义,而没有本体数据. 唯心主义上而言,没有实体,只有意志,游戏一样跑下去,只是看不到图像. 进而带来的好处是,如果一个建筑的数据还没完成IO,其3D对应资源还没建立,那建筑内的Model也不会被加载.建筑的3D资源在主线程被构造时,需要加载其关联/依赖的Model资源,这个加载也是异步的,所以不会卡住,从而形成嵌套循环的异步加载过程,最终的显示结果对象逐个显示出来,相当地有趣. 所以,当异步加载地图,引发异步加载模型,异步加载世界物件,又引发异步加载纹理对象. 假设卡住模型加载时的IO线程,那么游戏还是会运行,只是看不到模型,模型的碰撞检测也失效,如果用多线程IO呢? OpenGL的name机制很适合做空对象,glGenXXX只是生成一个空对象,在没加载数据前,用其调用渲染也不会出错,只是白色或没图像而已,等数据从异步线程出来了,图像就出来的. 然而,对于更复杂的流式逻辑,空对象模式也难以应用多线程加载,比如人物换装纹理的构建一定要求即时加载纹理,武器绑定要求人体的模型已经建立,才知道绑定到哪个socket,让我觉得复杂游戏玩家的外观难以异步加载.进入wow中时,玩家人物总是最后一步被加载显示出来的,有服务器的原因,估计也有客户端的同步加载原因.当有新人进入视野时,机器有时还是会卡一下的. 在Opengl.org上看到一个很新奇的技术,跟wow有关, World of Warcraft update adds mult-threaded OpenGL on Intel iMacs running OS X 10.4.8 or higher. Depending on hardware, scene and graphical settings, this can raise frame rates up to a factor of 2X. 技术文档出处: http://developer.apple.com/technotes/tn2006/tn2085.html
若A.exe静态链接B.dll,B.dll使用static HMODULE hDLL = ::LoadLibrary("C.dll");加载C.dll,则若C.dll加载失败,则A.exe出现"应用程序正常初始化(0xC0000005)失败.请单击"确定",终止应用程序."
为避免 static HMODULE hRenderCraftDLL = ::LoadLibrary("C.dll");在程序一启动就运行加载,将其改为
inline static HMODULE GetRenderCraftDLL()
{
static HMODULE hRenderCraftDLL = ::LoadLibrary("RenderCraft.dll");
return hRenderCraftDLL;
}
用函数来实现延迟加载的技巧.
sc create SVNService binpath= "D:\subversion\bin\svnserve.exe --service -r D:\svnroot" displayname= "SVNService" depend= Tcpip
切记:=号前无空格,=号有空格.
==========================
配置authz:
[groups]
admin=linghuye
[/]
@admin=rw
==========================
配置svnserve:
anon-access = none
auth-access = write
password-db = passwd
authz-db = authz
==========================
Global ignore pattern:
*.obj *.pch *.pdb *.ilk *.exp *.trg *.tmp *.plg *.bsc *.sbr *.aps *.ncb *.7z */Objs *\Objs */Debug */Debug
==========================
允许修改版本的Log:
在版本库hooks目录下建立pre-revprop-change.bat文件,内容:
@exit 0
==========================
忽略本地版本目录中的其他文件和目录
目录property设置如: svn:ignore Objs
实践之后才会觉得书中的每句话都富有含意,总结以备忘.1. Light Mapping, 光照贴图,准确地说是漫反射光照贴图,所以也有简称反射贴图的.
按<Realtime Rendering> 定义如下: For static lighting in an environment, the diffuse component on any surface remains the same from any angle. Because of this view-independence, the contribution of light to a surface could be captured in a texture structure attached to a surface. By using a seperate, precomputed texture that captured the lighting contributions, and multiplying it with the underlying surface, one can achieve Phong-like shading. Reference: http://www.flipcode.com/articles/article_lightmapping.shtml2.AphaMapping,Alpha贴图,Before testing and replacing the Z-buffer value, there needs to be a test of the alpha value. If alpha is 0, then nothing further is done for the pixel. If this additional test is not done, the tree's background color will not affect the pixel's color, but will potentially affect the z-value, which can lead to rendering errors.
3.Gloss mapping: A gloss map is a texture that changes the contribution of the specular component over the surface.
4.Cube Map:
A. Reflective surface need mapping locations on the object's surface to the appropriate reflected direction in the 360 degree environment surrounding the object.
B.The texturing enable priority is cube map, 3D, 2D, and finally 1D.
C.立方图非常适用于实现环境,反射和光照效果,立方图还可以把纹理环绕到球体上,使纹理单元均匀地分布于它的各个面上.
5.Shere Env Map
A.Also called reflection mapping
B.All EM start with a ray from the viewer to a point on the reflector. This ray is then reflected with respect to the normal at that point. Instead of finding the intersection with the closest surface, as ray tracing does, EM uses the direction of the reflection vector as an index to an image containing the environment.
C.Shere EM is view-dependent meaning that a different sphere map texture image is required for each different eye position. Additionally, sphere mapping is subject to unsightly "speckle" artifacts at the glancing edges of sphere mapped objects.
6.Dot3 Bump Map
A.
References: <Realtime Rendering>
http://developer.nvidia.com/object/cube_map_ogl_tutorial.html 游戏编程精粹5.6
|